Развёртывание Kubernetes в производственной среде требует не просто установки кластера — необходимо с самого начала принять правильные архитектурные решения, от которых будут зависеть масштабируемость, доступность и управляемость платформы. Вебинар специалистов Broadcom Professional Services и MomentumAI посвящён ключевым принципам проектирования VMware vSphere Kubernetes Service (VKS) поверх VMware Cloud Foundation (VCF). Докладчики — Vijay Appani, Solution Architect компании Broadcom, и Caleb Washburn, CTO и основатель MomentumAI — рассматривают проверенные шаблоны проектирования, которые их команды применяют в реальных enterprise-проектах.
Что такое VKS и зачем запускать Kubernetes на VCF
VMware vSphere Kubernetes Service (VKS) — это встроенный механизм запуска Kubernetes на платформе vSphere, интегрированный непосредственно в VMware Cloud Foundation. В отличие от сторонних дистрибутивов, VKS использует подтверждённую CNCF версию Kubernetes и глубоко интегрирован с инфраструктурными компонентами VCF: вычислительным слоем (vSphere), сетью (NSX) и хранилищем (vSAN). Это позволяет организациям строить современную private cloud-платформу, избегая «лоскутных» решений и накапливаемого технического долга.
Ключевая идея заключается в том, что VCF предоставляет единую платформу, объединяющую ресурсы compute, network и storage в согласованный операционный слой. Kubernetes в таком окружении получает доступ к корпоративным политикам хранения, сетевой изоляции на уровне неймспейсов и интеграции с порталом самообслуживания VCF Automation — всё это без необходимости разворачивать и поддерживать внешние инструменты.
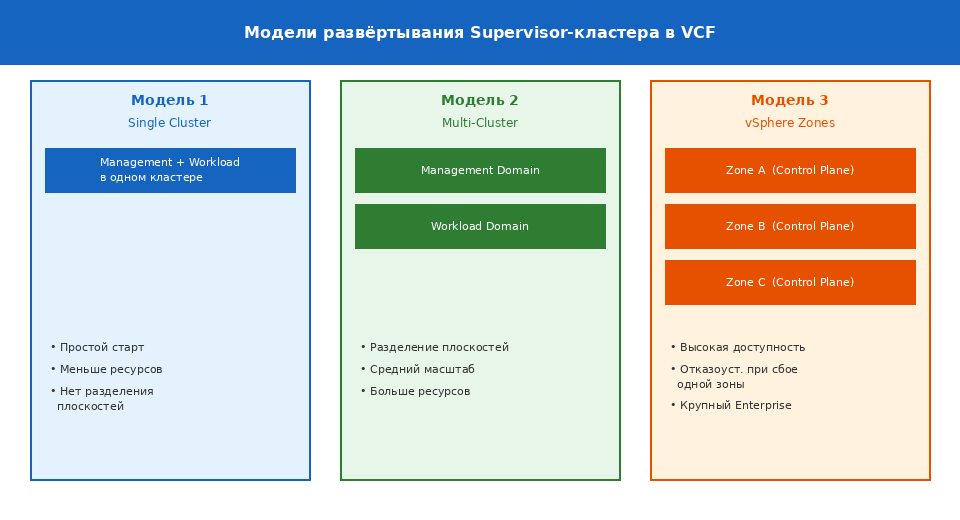
Три модели развёртывания Supervisor-кластера
Центральным компонентом VKS является Supervisor-кластер — уровень управления Kubernetes, развёртываемый поверх рабочего домена VCF. Существует три основные топологии его размещения, и выбор между ними определяет поведение платформы при сбоях, требования к ресурсам и сложность эксплуатации.
Модель 1: Single Cluster. Supervisor-кластер и рабочие нагрузки размещаются в одном vSphere-кластере. Это наиболее простой с точки зрения конфигурации вариант. Он подходит для начального знакомства с платформой или сред разработчиков, однако не обеспечивает разделения плоскости управления и плоскости данных. При сбое кластера теряется и управление, и рабочие нагрузки.
Модель 2: Multi-Cluster с разделёнными зонами. Supervisor-контрольная плоскость развёртывается в отдельном управляющем домене, а рабочие нагрузки — в выделенных рабочих доменах. Такое разделение обеспечивает независимость управляющего слоя от прикладного, что принципиально важно для инфраструктуры среднего масштаба. Недостатком является необходимость большего числа хостов и более сложная настройка сети и зон.
Модель 3: vSphere Zones (рекомендуется для enterprise). Виртуальные машины управляющей плоскости Supervisor-кластера распределяются по трём vSphere Zones — логическим группам, каждая из которых соответствует отдельному физическому кластеру. Рабочие нагрузки могут совместно использовать те же три зоны или размещаться в выделенных. Платформа выдерживает полный отказ одной зоны без потери доступности — ни управляющий слой, ни приложения не затрагиваются. Данная модель рекомендуется для крупных enterprise-развёртываний, требующих гарантий высокой доступности на уровне инфраструктуры.
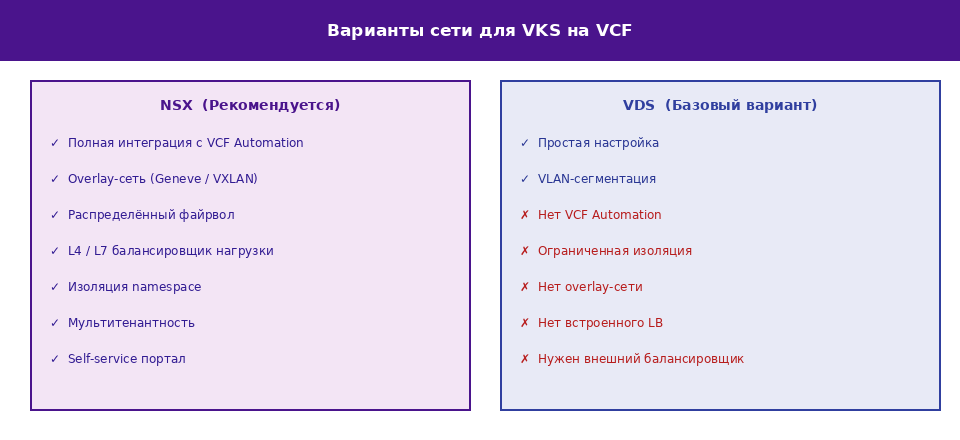
Сетевые опции: NSX или VDS
При настройке сети для VKS на VCF доступны два варианта: NSX и vSphere Distributed Switch (VDS). Выбор между ними оказывает существенное влияние на функциональность платформы и возможности автоматизации.
NSX является рекомендованным выбором для любого нового (greenfield) развёртывания VCF. Overlay-сеть на основе Geneve/VXLAN обеспечивает полную изоляцию на уровне неймспейсов, встроенный распределённый файрвол, встроенный балансировщик нагрузки уровней L4 и L7 (NSX Advanced Load Balancer / AVI), а также глубокую интеграцию с VCF Automation. Именно NSX позволяет реализовать портал самообслуживания, где разработчики и команды самостоятельно запрашивают ресурсы, не взаимодействуя напрямую с vSphere-администраторами.
VDS применяется в случаях, когда NSX не может быть развёрнут — например, при модернизации существующей инфраструктуры или при строгих ограничениях лицензирования. VDS поддерживает базовые возможности VKS, однако не поддерживает VCF Automation, overlay-сети и встроенный балансировщик нагрузки. При использовании VDS в производственной среде потребуется внешний балансировщик, что добавляет операционную сложность.
Отдельно подчёркивается, что если требования к приложению предполагают L4 или L7 балансировку, использование выделенного балансировщика нагрузки является обязательным — независимо от выбранного сетевого варианта.
Хранилище: vSAN, политики и управление томами
Хранилище в архитектуре VKS разделяется на два типа: эфемерное (ephemeral) и постоянное (persistent). Эфемерное хранилище используется для дисков самих узлов Kubernetes (Control Plane VMs и Worker Nodes) и временных томов Pod'ов. Оно берётся из основного или дополнительного хранилища рабочего домена и настраивается при активации Supervisor-кластера.
Постоянные тома (Persistent Volumes, PV) предназначены для stateful-приложений — баз данных, очередей сообщений, систем хранения состояния. Доступ к постоянному хранилищу управляется через Storage Policies — политики хранения vSAN, которые администратор создаёт в vCenter. Политики описывают параметры производительности, доступности (RAID-1, RAID-5/6) и шифрования. Каждый арендатор (tenant) в мультитенантной конфигурации получает доступ только к тем политикам хранения, которые ему явно назначены.
Если арендатору не назначена ни одна storage policy, он не сможет создавать Persistent Volume Claims (PVC) — это удобный механизм ограничения: организации могут предоставлять namespace без прав на stateful-хранение там, где это нежелательно. Поддерживаются режимы доступа RWO (ReadWriteOnce) и RWX (ReadWriteMany) — последний обычно требует дополнительных компонентов типа vSAN File Services или внешних NFS-решений.
Мультитенантность и интеграция с VCF Automation
Одним из ключевых преимуществ VKS на VCF является встроенная поддержка мультитенантности через механизм namespace и интеграцию с VCF Automation. Каждый неймспейс представляет собой изолированную рабочую область, которой могут быть назначены: квоты на CPU и RAM, доступные storage policies, сетевые профили NSX, а также права доступа пользователей или групп из Active Directory / LDAP.
VCF Automation предоставляет портал самообслуживания, через который подразделения и команды разработчиков могут самостоятельно запрашивать Kubernetes namespace, инициировать развёртывание приложений и управлять ресурсами — без участия администратора vSphere. Платформа автоматически создаёт необходимые ресурсы: сетевые сегменты NSX, политики хранения, RBAC-права. Это, по словам авторов вебинара, является «новейшим и наиболее зрелым способом организации современного private cloud».
Рекомендуется начинать с NSX в качестве сетевого стека при любом новом greenfield-развёртывании VCF именно потому, что VCF Automation поддерживает только NSX, и без него модель самообслуживания недоступна.
Рекомендации по проектированию production-платформы
По итогам вебинара сформулированы следующие практические рекомендации для команд, проектирующих VKS на VCF в производственной среде:
Используйте топологию vSphere Zones для любого развёртывания с требованиями к высокой доступности — она обеспечивает автоматический failover при отказе целого кластера без вмешательства администратора.
Выбирайте NSX как сетевой стек при greenfield-развёртывании — только с NSX доступна полная интеграция с VCF Automation и портал самообслуживания.
Планируйте storage policies заранее: определите требования к производительности и отказоустойчивости для разных классов рабочих нагрузок ещё до запуска первых неймспейсов.
Разграничивайте доступ к хранилищу на уровне арендаторов — не назначайте storage policies тем неймспейсам, которым stateful-хранение не нужно.
Если среда требует L4/L7 балансировки, включайте NSX Advanced Load Balancer (AVI) в архитектуру с самого начала — добавить его позднее значительно сложнее.
Не смешивайте управляющую и рабочую плоскости в одном кластере для производственной среды: выделяйте отдельный рабочий домен для приложений, даже если это требует дополнительных хостов.
Вопросы и ответы: ключевые моменты
В ходе сессии вопросов и ответов слушателей интересовали несколько практических аспектов. На вопрос о поддержке собственных сервисов поверх VKS ответ был однозначным: технически это возможно, однако рекомендуется использовать интегрированный стек — vSAN, NSX и VCF Automation — поскольку именно на нём строится поддержка и будущее развитие платформы.
На вопрос об источниках эфемерного хранилища пояснялось, что при активации Supervisor-кластера администратор указывает datastore, из которого берётся эфемерное хранилище для узлов Kubernetes и временных томов Pod'ов. Это может быть как vSAN, так и дополнительное (supplemental) хранилище рабочего домена.
Относительно нестандартных конфигураций — в частности, развёртывания VKS поверх существующей vSphere-среды без полного стека VCF — авторы отметили, что такие варианты существуют, но лишены ключевых преимуществ интегрированной платформы: автоматизации, самообслуживания и единого управления жизненным циклом.
Итог
VMware vSphere Kubernetes Service на VMware Cloud Foundation представляет собой зрелую enterprise-платформу для запуска production-Kubernetes с полной интеграцией в корпоративную инфраструктуру. Правильный выбор топологии Supervisor-кластера, сетевого стека и модели хранения на этапе проектирования определяет, насколько легко платформа будет масштабироваться и насколько просто её будет эксплуатировать в долгосрочной перспективе. Ознакомиться с предстоящими вебинарами серии VCF можно по ссылке go-vmware.broadcom.com/VCFWebinars.
Современный разработчик привык к беспрепятственному доступу к инфраструктуре. В публичном облаке достаточно нажать кнопку или вызвать API — и через несколько минут кластер Kubernetes, виртуальная машина или база данных готовы к работе. Но что происходит, когда требования к суверенитету данных, соответствию нормативным требованиям или прогнозируемости затрат обязывают развёртывать нагрузки на собственной инфраструктуре?
Исторически онпрем-инфраструктура означала создание заявок в IT-систему и ожидание ресурсов в течение дней или даже недель. Такие задержки превращались в серьёзное препятствие для вывода продуктов на рынок. Разработчики, уставшие от очередей, нередко поднимали собственные «теневые» базы данных на неуправляемых виртуальных машинах — только чтобы двигаться быстрее. Результатом становились бесконтрольное разрастание баз данных, дрейф конфигураций, отсутствие управления и серьёзные угрозы безопасности.
Платформенная инженерия на базе VMware Cloud Foundation (VCF) изменила эту картину. Используя платформу частного облака VCF, организации могут устранить разрыв между IT-операциями и командами разработчиков. VCF обеспечивает настоящее «от платформы до данных» самообслуживание, сравнимое с возможностями публичного облака: разработчики получают нужную им скорость, а платформенные инженеры — централизованное управление всем парком ресурсов.
Соответствие публичному облаку: эквиваленты на on-prem VCF
Чтобы оценить возможности VCF как платформы частного облака, полезно сопоставить её функциональность с сервисами публичного облака, которые разработчики уже хорошо знают. Для тех, кто работал с AWS, on-prem-эквиваленты в VCF выглядят следующим образом:
Amazon EC2 > VCF VM Service: позволяет разработчикам декларативно развёртывать традиционные виртуальные машины и управлять ими совместно с контейнерами.
Amazon EKS > VCF VKS (vSphere Kubernetes Service): предоставляет конформные Kubernetes-кластеры с самообслуживанием, нативно встроенные в VCF.
Amazon RDS > VCF DSM (Data Services Manager): реализует инструмент управления парком баз данных в режиме Database-as-a-Service (DBaaS) по запросу.
Совместное использование этих трёх компонентов позволяет платформенным командам предлагать разработчикам комплексный каталог сервисов, управляемый через API, непосредственно из собственного датацентра.
Рабочий процесс платформенного инженера: установка границ
Архитектурный принцип этого решения — управление через персоны. Системный администратор или платформенный инженер определяет «правила игры» и сохраняет контроль, а разработчик потребляет ресурсы строго в заданных рамках. Рабочий процесс устроен следующим образом.
1. Создание границ. Администратор инфраструктуры создаёт vSphere namespace в VCF. Этот namespace выступает границей tenancy: к конкретному проекту или команде разработчиков привязываются лимиты вычислительных ресурсов, памяти и хранилища.
2. Определение инфраструктуры и политик. В рамках namespace платформенный инженер задаёт правила взаимодействия:
Вычислительные ресурсы: размеры кластеров, пулы ресурсов и классы ВМ (размеры: small, medium, large) — чтобы разработчики не превышали допустимое потребление.
Хранилище и сеть: конкретные политики хранения (vSAN или NFS) и привязка нагрузок к нужным VLAN и VPC-подсетям.
Сервисы данных в DSM: разрешённые движки баз данных и их версии, предварительно проверенные командой DBA.
Опыт разработчика: развёртывание в режиме самообслуживания
После того как администратор задал политики, платформенный инженер открывает доступ команде разработки через защищённый API-токен. С этого момента разработчики полностью самостоятельны — никакого ожидания в очереди задач и утверждений. Используя стандартный инструментарий Kubernetes (kubectl), портал или API DSM либо собственные Terraform-пайплайны, они могут:
поднять новый Kubernetes-кластер (VKS) для тестирования микросервисов;
выбрать движок базы данных — PostgreSQL, MySQL или Microsoft SQL Server (появится в версии 9.1).
При этом все самостоятельно подготовленные ресурсы автоматически соответствуют корпоративным политикам резервного копирования, сети и безопасности, установленным администратором.
Автоматизация и интеграция с Infrastructure-as-Code
Всю описанную среду можно полностью автоматизировать с помощью подхода Infrastructure as Code. Платформенная команда может управлять пространствами имен и конфигурациями сервисов через различные инструменты в зависимости от предпочтений: Kubernetes CRD, Terraform-манифест или корпоративный блупринт, охватывающий целый комплекс ресурсов — VKS-кластер с набором виртуальных машин, сервисы данных DSM и даже ArgoCD для доставки приложений в VKS-кластеры — всё в рамках единого набора API-вызовов.
Ниже — пример CRD для декларативного развёртывания базы данных в namespace, демонстрирующий простоту этого подхода. CRD можно использовать как часть GitOps-процесса:
День второй: операционное управление после запуска
Одно из наиболее значимых преимуществ платформенного подхода, особенно с Data Services Manager, состоит в том, что он не заканчивается на первоначальном «нажатии кнопки». Платформа автоматизирует критически важные операции второго дня жизненного цикла — когда приложению предстоит выйти в продуктив. Задачи, которые традиционно поглощали ресурсы DBA, теперь решаются простым изменением декларативного параметра в CRD:
Высокая доступность: автоматическое развёртывание кластеров для немедленной отказоустойчивости.
Масштабируемость: возможность легко добавлять read-реплики по мере роста нагрузки на приложение.
Защита данных: автоматическое резервное копирование и восстановление до точки во времени (PITR) — «из коробки».
Управление: централизованная видимость для платформенной команды с контролем использования и устранением разрастания баз данных по всем рабочим доменам.
Поддержка OSS-баз данных корпоративного уровня: DSM предоставляет возможности и поддержку коммерческого класса, недоступные в бесплатных open-source версиях PostgreSQL или MySQL.
Заключение
Создание каталога самообслуживания — от платформы до данных — не требует переноса всего в публичное облако. Используя VCF, VKS и DSM, организации получают гибкость публичного облака в сочетании с безопасностью и контролем собственной частной инфраструктуры. Платформенные инженеры при этом трансформируются из ИТ-привратников в enabler'ов — обеспечивая разработчиков API-эндпоинтами, Kubernetes-кластерами и управляемыми базами данных, необходимыми для более быстрой и безопасной разработки ПО, готового к производственному окружению.
В новом видео на канале Gnan Cloud Garage подробно разобраны ключевые отличия между VMware Cloud Foundation (VCF) версии 5.2 и VCF 9.0, причем автор подчеркивает: речь идёт не о простом обновлении, а о кардинальной архитектурной переработке платформы.
VCF — это флагманская платформа частного облака от компании VMware, объединяющая вычисления, сеть, хранилище, безопасность, автоматизацию и управление жизненным циклом в едином программно-определяемом стеке. В версии 9.0 VMware делает шаг в сторону «облачного» подхода, ориентированного на масштаб, автоматизацию и гибкость.
Основные отличия VCF 5.2 и VCF 9.0
1. Модель развертывания
VCF 5.2: установка строилась вокруг SDDC Manager и требовала загрузки Cloud Builder размером около 20 ГБ. Развёртывание компонентов происходило последовательно.
VCF 9.0: представлен новый VCF Installer (~2 ГБ) и fleet-based модель. Это обеспечивает более быстрое развертывание, модульную архитектуру и гибкость с первого дня.
Результат: ускорение внедрения и переход от монолитного подхода к модульному.
2. Управление жизненным циклом (LCM)
VCF 5.2: весь LCM был сосредоточен в SDDC Manager.
VCF 9.0: управление разделено между Fleet Management Appliance и SDDC Manager.
Fleet Management отвечает за операции, автоматизацию и управление идентификацией.
SDDC Manager фокусируется на базовой инфраструктуре.
Результат: параллельные обновления, меньшее время простоя и более точный контроль.
3. Управление идентификацией
VCF 5.2: использовались Enhanced Linked Mode и vCenter Identity.
VCF 9.0: внедрены VCF Single Sign-On и VCF Identity Broker, обеспечивающие единую систему идентификации для всех компонентов.
Результат: действительно унифицированная и современная модель identity management.
4. Лицензирование
VCF 5.2: традиционные лицензии — по продуктам и ключам (vSphere, NSX, vSAN, Aria).
VCF 9.0: keyless subscription model — без ключей, с подпиской.
Результат: упрощённое соответствие требованиям, обновления и соответствие современным облачным моделям потребления.
VCF 9.0: операции встроены по умолчанию, обеспечивая fleet-wide мониторинг и compliance «из коробки».
6. Автоматизация
VCF 5.2: автоматизация была дополнительной опцией.
VCF 9.0: решение VCF Automation встроено и оптимизировано для:
AI-нагрузок
Kubernetes
виртуальных машин
Результат: платформа самообслуживания, полностью готовая для разработчиков.
7. Сеть
VCF 5.2: NSX — опциональный компонент.
VCF 9.0: NSX становится обязательным для management и workload-доменов.
Результат: единая программно-определяемая сетевая архитектура во всей среде VCF.
8. Хранилище
VCF 5.2: поддержка vSAN, NFS и Fibre Channel SAN.
VCF 9.0: акцент на vSAN ESA (Express Storage Architecture) и Original Storage Architecture, с планами по расширению поддержки внешних хранилищ.
Результат: фундамент для более современной и производительной storage-архитектуры.
9. Безопасность и соответствие требованиям
VCF 5.2: ручное управление сертификатами и патчами.
VCF 9.0: встроенные средства управления:
унифицированное управление ключами
live patching
secure-by-default подход
Результат: серьёзная модернизация безопасности и Zero Trust по умолчанию.
10. Модель обновлений
VCF 5.2: последовательные апгрейды.
VCF 9.0: параллельные обновления с учётом fleet-aware LCM.
Результат: меньше простоев и лучшая предсказуемость обслуживания.
11. Kubernetes и контейнеры
VCF 5.2: ограниченная поддержка Tanzu.
VCF 9.0: нативный Kubernetes через VCF Automation.
Результат: единая платформа для VM и Kubernetes — полноценная application platform.
12. Импорт существующих сред
VCF 5.2: импорт существующих vSphere/vCenter не поддерживался.
VCF 9.0: можно импортировать существующие окружения как management или workload-домены.
Результат: упрощённая миграция legacy-нагрузок в современное частное облако.
Итог
VCF 5.2 — это классическая платформа частного облака с опциональными возможностями, ну а VCF 9.0 — это современное, cloud-like частное и гибридное облако, ориентированное на масштабирование, автоматизацию и управление флотом инфраструктуры.
Как подчёркивает автор видео, VCF 9.0 — это не апгрейд, а полноценный редизайн, нацеленный на лучший пользовательский опыт и соответствие требованиям современных enterprise и облачных сред.
vSAN File Services — это встроенная в vSAN опциональная функция, которая позволяет организовать файловые расшаренные ресурсы (файловые шары) прямо «поверх» кластера vSAN. То есть, вместо покупки отдельного NAS-массива или развертывания виртуальных машин-файловых серверов, можно просто включить эту службу на уровне кластера.
После включения vSAN File Services становится возможным предоставить SMB-шары (для Windows-систем) и/или NFS-экспорты (для Linux-систем и cloud-native приложений) прямо из vSAN.
Основные возможности и сильные стороны
Вот ключевые функции и плюсы vSAN File Services:
Возможность / свойство
Что это даёт / когда полезно
Поддержка SMB и NFS (v3 / v4.1)
Можно обслуживать и Windows, и Linux / контейнерные среды. vSAN превращается не только в блочное хранилище для виртуальных машин, но и в файловое для приложений и пользователей.
Файл-сервисы без отдельного «файлера»
Нет нужды покупать, настраивать и поддерживать отдельный NAS или физическое устройство — экономия затрат и упрощение инфраструктуры.
Лёгкость включения и управления (через vSphere Client)
Администратор активирует службу через привычный интерфейс, не требуются отдельные системы управления.
До 500 файловых шар на кластер (и до 100 SMB-шар)
Подходит для сравнительно крупных сред, где нужно много шар для разных подразделений, проектов, контейнеров и другого.
Распределение нагрузки и масштабируемость
Служба развёрнута через набор «протокол-сервисов» (контейнеры / агенты), которые равномерно размещаются по хостам; данные шар распределяются как vSAN-объекты — нагрузка распределена, масштабирование (добавление хостов / дисков) + производительность + отказоустойчивость.
Интегрированная файловая система (VDFS)
Это не просто «виртуальные машины + samba/ganesha» — vSAN использует собственную распределённую FS, оптимизированную для работы как файловое хранилище, с балансировкой, метаданными, шардированием и управлением через vSAN.
Мониторинг, отчёты, квоты, ABE-контроль доступа
Как и для виртуальных машин, для файловых шар есть метрики (IOPS, latency, throughput), отчёты по использованию пространства, возможность задать квоты, ограничить видимость папок через ABE (Access-Based Enumeration) для SMB.
Поддержка небольших кластеров / 2-node / edge / remote sites
Можно применять даже на «граничных» площадках, филиалах, удалённых офисах — где нет смысла ставить полноценный NAS.
Когда / кому это может быть особенно полезно
vSAN File Services может быть выгоден для:
Организаций, которые уже используют vSAN и хотят минимизировать аппаратное разнообразие — делать и виртуальные машины, и файловые шары на одной платформе.
Виртуальных сред (от средних до крупных), где нужно предоставить множество файловых шар для пользователей, виртуальных машин, контейнеров, облачных приложений.
Сценариев с контейнерами / cloud-native приложениями, где требуется RWX (Read-Write-Many) хранилище, общие папки, persistent volumes — все это дают NFS-шары от vSAN.
Удалённых офисов, филиалов, edge / branch-site, где нет смысла ставить отдельное файловое хранилище.
Случаев, когда хочется централизованного управления, мониторинга, политики хранения и квот — чтобы всё хранилище было в рамках одного vSAN-кластера.
Ограничения и моменты, на которые нужно обратить внимание
Нужно учитывать следующие моменты при планировании использования:
Требуется выделить отдельные IP-адреса для контейнеров, которые предоставляют шары, плюс требуется настройка сети (promiscuous mode, forged transmits).
Нельзя использовать одну и ту же шару одновременно и как SMB, и как NFS.
vSAN File Services не предназначен для создания NFS датасторов, на которые будут смонтированы хосты ESXi и запускаться виртуальные машины — только файловые шары для сервисов/гостевых систем.
Если требуется репликация содержимого файловых шар — её нужно организовывать вручную (например, средствами операционной системы или приложений), так как vSAN File Services не предлагает встроенной гео-репликации.
При кастомной и сложной сетевой архитектуре (например, stretched-кластер) — рекомендуется внимательно проектировать размещение контейнеров, IP-адресов, маршрутизации и правил site-affinity.
Технические выводы для администратора vSAN
Если вы уже используете vSAN — vSAN File Services даёт возможность расширить функциональность хранения до полноценного файлового — без дополнительного железа и без отдельного файлера.
Это удобно для унификации: блочное + файловое хранение + облачные/контейнерные нагрузки — всё внутри vSAN.
Управление и мониторинг централизованы: через vSphere Client/vCenter, с известными инструментами, что снижает операционную сложность.
Подходит для «гибридных» сценариев: Windows + Linux + контейнеры, централизованные файлы, общие репозитории, home-директории, данные для приложений.
Можно использовать в небольших и распределённых средах — филиалы, edge, remote-офисы — с минимальным оверхэдом.
«Альт Виртуализация» — это российское решение для построения и управления виртуальной инфраструктурой. Недавно вышедший релиз Альт Виртуализации версии 11.0 базируется на Proxmox VE 8.4 и предлагает унифицированный способ работы с виртуальными машинами (KVM/QEMU) и контейнерами (LXC) через веб-интерфейс, CLI и API. Поддерживаются архитектуры x86_64 и AArch64. Продукт включён в Реестр отечественного ПО Минцифры (рег.№ 6487) и выпускается в редакционном формате: сейчас доступна только PVE-версия, облачная готовится.
Основная функциональность продукта
1. Виртуализация серверов:
Полноценная аппаратная виртуализация под KVM/QEMU.
Лёгкие контейнеры LXC с поддержкой cgroups/namespaces.
2. Кластеризация и HA – обновлённая кластерная файловая система (pmxcfs), живая миграция, механизмы высокой доступности.
3. Сетевая инфраструктура – Linux bridge, Open vSwitch, VLAN, bonding, а теперь SDN с поддержкой VXLAN, QinQ и виртуальных сетей (VNets).
4. Хранилища – поддержка локальных (LVM, ZFS) и сетевых хранилищ (NFS, iSCSI, Ceph, GlusterFS и др.).
5. Резервное копирование – встроенные средства + интеграция с Proxmox Backup Server 3.3.
6. Безопасность и аутентификация – механизм ролевого доступа RBAC, поддержка PAM, LDAP, MS AD/Samba DC, OpenID Connect; OpenSSL 3.3 обеспечивает повышенную безопасность.
7. Поддержка GPU/PCI passthrough – возможность напрямую передавать устройства в ВМ.
8. Интеграция и API – единый Web GUI, CLI (с автодополнением), RESTful API на JSON для внешних интеграций.
Новшества в версии Альт Виртуализация 11.0
1. Улучшенный установщик
Быстрая установка с выбором файловых систем Ext4 или Btrfs (RAID 0/1/10), автоматическим созданием LVM-thin.
Интегрированный сетевой раздел с поддержкой VLAN, автоматическим мостом vmbr0, DNS и доменами.
2. SDN-подсистема
Полная поддержка SDN: создание виртуальных сетевых зон, сегментаций, изоляции, VNets и управление трафиком.
3. Графический апдейт
Из веб-интерфейса можно подключать и отключать репозитории, обновлять систему и пакеты без CLI.
4. Упрощённая архитектура
Контейнеризация на базе Kubernetes, Docker, CRI-O, Podman вынесена в «Альт Сервер 11.0», что позволило повысить стабильность и упрощённость PVE-системы.
Для виртуализации остался только LXC.
5. Импорт из VMware ESXi
Новый инструмент упрощает миграцию: импортирует VMDK + конфигурации сети и дисков напрямую из ESXi.
6. Обновление компонентов
Основные версии: PVE 8.4, LXC 6.0, QEMU 9.2, Ceph 19.2, Open vSwitch 3.3, Corosync 3.1, ZFS 2.3, OpenSSL 3.3.
Зачем всё это нужно
Быстрая и простая установка снижает порог входа и риски ошибок.
SDN-поддержка позволяет строить сложную и безопасную сетевую инфраструктуру без стороннего ПО.
Гибкое обновление через GUI упрощает эксплуатацию.
Упрощённая среда без лишних контейнерных инструментов — более надёжна и менее уязвима.
Прямая миграция с VMware облегчает переход на отечественные решения.
Современные компоненты поднимают производительность, безопасность и совместимость.
Заключение
«Альт Виртуализация 11.0» — важный шаг вперёд для российской виртуализации. Упрощённая установка, расширенные сетевые возможности, интеграция с системами резервного копирования и удобное обновление делают платформу достойным решением для корпоративного уровня. Первоначальный фокус на PVE-редакции с дальнейшим выходом облачной версии обеспечит гибкость и масштабируемость.
Одной из ключевых инженерных инициатив в VMware Cloud Foundation 9 (VCF 9) стало улучшение пользовательского опыта при развертывании. VMware не только упростила процесс развертывания нового экземпляра VCF, но и расширила поддержку различных типов топологий и сценариев развертывания. В результате пользователи vSphere получают более простой, быстрый и воспроизводимый процесс перехода на VCF.
VMware Cloud Foundation 9 предлагает несколько вариантов развертывания для модернизации инфраструктуры:
Развертывание нового экземпляра VCF
Расширение существующего пула VCF (VCF Fleet)
Конвертация существующего развертывания vCenter в VCF
Импорт существующего развертывания vCenter в VCF
Начнём с того, как происходит развертывание и масштабирование VCF 9.
VMware Cloud Foundation 9 — это крупный релиз, включающий ряд важных новых возможностей и более интегрированный опыт для администраторов частных облаков. Виртуальный модуль установщика VMware Cloud Foundation (VCF Installer) — это новый компонент в VCF 9, предоставляющий более гибкие сценарии развертывания, подходящие для расширенного набора задач.
VCF Installer можно использовать для:
Развертывания нового экземпляра VCF как части нового пула (Fleet)
Если у заказчика уже есть несколько сред, он может развернуть дополнительные экземпляры VCF в существующем пуле.
Каждый экземпляр VCF развёртывается с использованием vSphere и сервера vCenter, NSX, VCF Operations и VCF Automation. Настройка VCF-среды с использованием vSAN обеспечивает полный стек SDDC (программно-определяемого датацентра).
VCF Installer также содержит встроенные рабочие процессы для конвертации (повторного использования) существующего развертывания vCenter в управляющий кластер VCF. В этом сценарии под существующей средой vCenter понимается развертывание вне VCF. При выполнении конвертации VCF Installer развертывается в том же кластере, где находится виртуальный модуль сервера vCenter. VMware поддерживает как кластеры vCenter, настроенные с vSAN, так и кластеры, использующие внешнее хранилище.
После конвертации среда становится полноценным экземпляром VCF, которым можно управлять, масштабировать и обслуживать на протяжении всего жизненного цикла как обычный VCF.
И это ещё не всё, что умеет VCF Installer. Рабочий процесс установщика также предоставляет возможность конвертировать существующий экземпляр VCF Operations и/или VCF Automation. Виртуальный модуль VCF Installer обеспечивает более простой, быстрый и воспроизводимый процесс перехода к VMware Cloud Foundation для клиентов.
Подробнее о виртуальном модуле VCF Installer
Виртуальный модуль VCF Installer заменяет Cloud Builder, использовавшийся в предыдущих версиях VCF. Он предоставляет гибкий набор опций, ещё больше упрощающих развертывание полноценной частной облачной среды.
VCF Installer содержит интерфейс с пошаговым управлением (UI-driven workflow) и больше не требует использования файла Deployment Parameters Workbook (таблица Excel). Также в него встроены функции конвертации и импорта существующих инстанций vCenter, VCF Operations и VCF Automation — без необходимости использовать скрипты VCF Import.
В предыдущих версиях Cloud Foundation требовалось устанавливать Aria Operations и Aria Automation отдельно и управлять ими на этапе Day 2 (после начального развертывания). Начиная с VCF 9, VCF Installer используется для развертывания всего стека VCF, включая гипервизор vSphere, хранилище, сеть, управление и самообслуживание, а VCF Operations отвечает за полное управление жизненным циклом этого стека.
Как работает VCF Installer?
В этом новом и очень легковесном виртуальном модуле VCF Installer встроен набор усовершенствованных сценариев развертывания и множество новых параметров конфигурации.
При подключении к порталу поддержки Broadcom пользователь загружает программные бинарные файлы, подключаясь к онлайн-репозиторию. В отличие от Cloud Builder, модуль VCF Installer не содержит бинарных файлов ПО.
Пользователи также могут настроить собственный автономный (offline) репозиторий, который можно использовать для нескольких экземпляров VCF. В этом случае бинарные файлы необходимо загрузить только один раз, что удобно при управлении несколькими экземплярами VCF.
После загрузки бинарных файлов модуль можно использовать для развертывания VMware Cloud Foundation (VCF) или VMware vSphere Foundation (VVF). Развертывание можно выполнить с помощью встроенного мастера установки или путем загрузки JSON-спецификации, которую можно повторно использовать, просматривать и валидировать через интерфейс. JSON-спецификацию также можно редактировать прямо в мастере установки.
Экземпляр VCF может быть развернут как часть нового пула (VCF Fleet) или добавлен к существующему пулу. VCF Fleet может включать в себя несколько развертываний VCF, использующих общие экземпляры VCF Operations и VCF Automation.
VCF Installer используется для начальной настройки управляющего кластера, который можно развернуть двумя способами:
Развертывание новых компонентов, включая виртуальные машины для vCenter Server, NSX, VCF Operations и VCF Automation.
Использование уже существующих компонентов, например, существующих экземпляров vCenter Server, VCF Operations и VCF Automation.
При выборе конвертации (повторного использования) существующего vCenter Server, VCF Installer конвертирует существующий кластер vSphere или vSphere с vSAN в управляющий кластер VCF. В рамках этого процесса VCF Installer автоматически развёртывает NSX.
Если выбран повторный запуск уже существующего экземпляра VCF Operations, рекомендуется указать тот vCenter Server, на котором он размещена, в качестве управляющего vCenter для первого кластера VCF.
Виртуальные машины для новых экземпляров VCF Operations, VCF Automation и NSX можно развернуть в двух режимах:
Простой режим (Simple Model) — одноузловые виртуальные модули.
Режим высокой доступности (High Availability Model) — несколько модулей для отказоустойчивости.
После успешного развертывания VCF Installer предоставляет ссылку для запуска VCF Operations, который используется для управления.
Подробнее о двух моделях виртуальных модулей
Простой режим (Simple Model)
Минимум 7 виртуальных модулей:
1 для vCenter Server
1 для SDDC Manager
1 для NSX Manager
3 для VCF Operations: Operations Manager, Fleet Management, Operations Collector
1 для VCF Automation
Если выбрана опция Supervisor, разворачивается виртуальный модуль VKS. Дополнительно после установки можно развернуть:
Поддержку логов в VCF Operations
Безопасное подключение к NSX Edge кластеру
Базу данных VIDB для управления доступом и идентификацией
Модель высокой доступности (High Availability Model)
Рекомендуется для производственных сред. Развертывается минимум 13 виртуальных модулей:
3 NSX Manager
3 VCF Operations
3 VCF Automation
3 для логов и 1 для VKS
Наличие трёх экземпляров каждого компонента обеспечивает отказоустойчивость при сбоях оборудования, уменьшает влияние обновлений и упрощает управление жизненным циклом (патчи, апгрейды и т.д.). Также доступны дополнительные опции (не указаны выше), например, настройка балансировщиков нагрузки NSX для отдельных компонентов.
В любое время после установки клиент может масштабировать дополнительные компоненты. Дополнительно можно развернуть:
VCF Operations for Networks
HCX
Другие дополнительные сервисы VCF Advanced (Add-ons)
Как управлять средой VCF 9?
Начиная с VCF 9, управление и эксплуатация частного облака выполняются через консоль VCF Operations. VCF Operations предоставляет администраторам облака единый и функционально насыщенный интерфейс, охватывающий управление вычислениями, хранилищем, сетью, флотом экземпляров и жизненным циклом всей системы.
Но и это ещё не всё - VCF Operations для VCF 9 также включает встроенные рабочие процессы, которые поддерживают ещё два дополнительных сценария развертывания VCF. С помощью VCF Operations можно:
Создавать новые домены рабочих нагрузок (workload domains)
Импортировать существующие развертывания vCenter в существующий экземпляр VMware Cloud Foundation
Оба варианта позволяют масштабировать частное облако и обеспечивают централизованное управление и эксплуатацию.
Импорт существующих развертываний vCenter в экземпляр VMware Cloud Foundation
VCF Operations упрощает добавление существующей инфраструктуры vSphere, vSAN и NSX в уже развернутый экземпляр VCF. В интерфейсе доступны интерактивные пошаговые сценарии импорта существующей инфраструктуры vSphere в VCF в виде доменов рабочей нагрузки.
Возможность импорта уже существующей инфраструктуры позволяет клиентам ускорить переход к VCF, использовать уже сделанные инвестиции и одновременно снижать затраты. Более того, теперь не требуется вручную переносить рабочие нагрузки со старой инфраструктуры на VCF.
При импорте развертывания vCenter в VCF, все кластеры внутри этого сервера vCenter автоматически импортируются и настраиваются как часть домена рабочей нагрузки.
Можно импортировать:
Кластеры vSphere с или без vSAN
Кластеры с или без NSX
Любую комбинацию этих компонентов
Если NSX в кластере ещё не развернут, он будет установлен автоматически в процессе конвертации.
При импорте развертывания vCenter в экземпляр VCF все кластеры, находящиеся на этом сервере vCenter, импортируются и настраиваются как часть домена рабочей нагрузки. Этот сценарий в VCF Operations поддерживает широкий спектр конфигураций кластеров, которые часто встречаются в существующих средах vSphere.
Совместимость по хостам:
Хосты с одним физическим сетевым адаптером (pNIC)
Кластеры с включённым LACP
Одноузловые кластеры и отдельные хосты (standalone)
Совместимость по хранилищу:
Кластеры vSAN из 2 узлов
HCI Mesh
Кластеры хранения vSAN
Растянутые кластеры vSAN (stretched clusters)
Также можно импортировать кластеры, использующие внешние хранилища, например:
NFS
VMFS over Fibre Channel (FC)
iSCSI
Совместимость по сети:
Развертывания vCenter Server, как с NSX, так и без него, могут быть импортированы
Резюме
VMware Cloud Foundation 9 (VCF 9) предлагает несколько вариантов развертывания для модернизации вашей инфраструктуры:
Новые развертывания:
Для нового развертывания VCF 9 требуется минимум 4 хоста для управляющего кластера, который может быть развернут с использованием vSAN, NFS или VMFS по FC.
Начиная с VCF 9, управляющий кластер можно настраивать с помощью узлов vSAN Ready Nodes (рекомендуется).
Также поддерживается оборудование vSphere, сертифицированное для использования с топологиями хранения на NFS/VMFS over FC. Подробности — в руководстве по совместимости (Compatibility Guide).
Управляющий домен нового экземпляра VCF настраивается с использованием NSX. Каждый рабочий домен (Workload Domain) также конфигурируется с NSX и готов к использованию виртуальной сети NSX (SDN).
Расширение существующего VCF Fleet:
Развертывание нового экземпляра VCF как части уже существующего пула.
Каждый VCF Fleet управляется общими экземплярами VCF Operations и VCF Automation.
Конвертация существующего развертывания vCenter в VCF:
VMware поддерживает конвертацию (повторное использование) существующих кластеров vSphere в VCF.
Такие среды могут быть развернуты с vSphere или vSphere с vSAN.
Среды vCenter с уже установленным NSX пока не поддерживаются для конвертации в управляющий домен VCF. В процессе будет установлен новый экземпляр NSX.
Требуется минимум:
3 узла vSAN Ready.
Или 2 хоста vSphere, настроенные с NFS или VMFS over FC (cм. VCF configmax для дополнительной информации).
Импорт развертывания vCenter в VCF:
Требуется минимум:
3 узла vSAN Ready.
Или 2 хоста vSphere, настроенные с NFS или VMFS over FC (cм. VCF configmax для дополнительной информации).
Существующие среды vCenter с установленным NSX могут быть импортированы как домены рабочей нагрузки.
Режим оценки:
Новый экземпляр VCF развертывается в режиме оценки (evaluation mode).
В этом режиме VCF полностью функционален и позволяет развертывать дополнительные хосты, домены рабочей нагрузки и кластеры.
Экземпляр VCF 9 необходимо активировать лицензией в течение 90 дней с момента установки.
VCF Operations направляет пользователя в Broadcom Business Services Console для завершения процесса лицензирования.
Управление VCF через VCF Operations:
Начиная с VCF 9, VCF Operations используется для управления одним или несколькими экземплярами VCF.
SDDC Manager 9 устанавливается или обновляется как компонент любого экземпляра VCF 9.
SDDC Manager будет выведен из эксплуатации в одном из будущих релизов.
Недавно мы рассказали об улучшениях и нововведениях платформы VMware Cloud Foundation 9.0, включающей в себя платформу виртуализации VMware vSphere 9.0 и средство создания отказоустойчивой инфраструктуры хранения VMware vSAN 9.0. Посмотрим теперь, что нового эти продукты включают с точки зрения сервисов хранилищ (Core Storage).
Улучшения поддержки хранилищ VCF
Для новых (greenfield) развёртываний VCF теперь поддерживаются хранилища VMFS, Fibre Channel и NFSv3 в качестве основных вариантов хранилища для домена управления. Полную информацию о поддержке хранилищ см. в технической документации VCF 9.
Улучшения NFS
Поддержка TRIM для NFS v3
Существующая поддержка команд TRIM и UNMAP позволяет блочным хранилищам, таким как vSAN и хранилища на базе VMFS, освобождать место после удаления файлов в виртуальной машине или при многократной записи в один и тот же файл. В типичных средах это позволяет освободить до 30% пространства, обеспечивая более эффективное использование ёмкости. С использованием плагина VAAI NFS системы NAS, подключённые через NFSv3, теперь могут выполнять освобождение пространства в VCF 9.
Шифрование данных в процессе передачи для NFS 4.1
Krb5p шифрует трафик NFS при передаче. Шифрование данных «на лету» защищает данные при передаче между хостами и NAS, предотвращая несанкционированный доступ и обеспечивая конфиденциальность информации организации, особенно в случае атак типа «man-in-the-middle». Также будет доступен режим Krb5i, который не выполняет шифрование, но обеспечивает проверку целостности данных, исключая их подмену.
Улучшения базовой подсистемы хранения
Сквозная (End-to-End, E2E) поддержка 4Kn
В версии 9.0 реализована поддержка E2E 4Kn, включающая:
Фронтэнд — представление виртуальных дисков (VMDK) с сектором 4K для виртуальных машин.
Бэкэнд — использование SSD-накопителей NVMe с 4Kn для vSAN ESA. OSA не поддерживает 4Kn SSD.
ESXi также получает поддержку 4Kn SSD с интерфейсом SCSI для локального VMFS и внешних хранилищ.
SEsparse по умолчанию для снимков с NFS и VMFS-5
Исторически, создание снимков (snapshots) имело значительное влияние на производительность ввода-вывода.
Формат Space Efficient Sparse Virtual Disks (SEsparse) был разработан для устранения двух основных проблем формата vmfsSparse:
Освобождение пространства при использовании снимков — SEsparse позволяет выполнять более точную и настраиваемую очистку места, что особенно актуально для VDI-сценариев.
Задержки чтения и снижение производительности из-за множественных операций чтения при работе со снимками.
Производительность была повышена благодаря использованию вероятностной структуры данных, такой как Bloom Filter, особенно для снимков первого уровня. Также появилась возможность настраивать размер блока (grain size) в SEsparse для соответствия типу используемого хранилища.
SEsparse по умолчанию применяется к VMDK объёмом более 2 ТБ на VMFS5, начиная с vSphere 7 Update 2. В vSphere 9 SEsparse становится форматом по умолчанию для всех VMDK на NFS и VMFS-5, независимо от размера. Это уменьшит задержки и увеличит пропускную способность чтения при работе со снимками. Формат SEsparse теперь также будет использоваться с NFS, если не используется VAAI snapshot offload plugin.
Поддержка спецификации vNVMe 1.4 — команда Write Zeroes
С выходом версии 9.0 поддержка NVMe 1.4 в виртуальном NVMe (vNVMe) позволяет гостевой ОС использовать команду NVMe Write Zeroes — она устанавливает заданный диапазон логических блоков в ноль. Эта команда аналогична SCSI WRITE_SAME, но ограничена только установкой значений в ноль.
Поддержка нескольких соединений на сессию iSCSI (Multiple Connections per Session)
Рекомендуется использовать iSCSI с Multi-path I/O (MPIO) для отказоустойчивого подключения к хостам. Это требует отдельных физических путей для каждого порта VMkernel и отказа от использования failover на базе состояния соединения или агрегацию сетевых интерфейсов (NIC teaming) или Link Aggregation Group (LAG), поскольку такие методы не обеспечивают детерминированный выбор пути.
Проблема: iSCSI традиционно использует одиночное соединение, что делает невозможным распределение трафика при использовании NIC teaming или LAG.
Решение — iSCSI с несколькими соединениями в рамках одной сессии, что позволяет:
Использовать несколько каналов, если один порт VMkernel работает в составе LAG с продвинутыми алгоритмами хеширования.
Повысить пропускную способность, когда скорость сети превышает возможности массива обрабатывать TCP через один поток соединения.
Важно: проконсультируйтесь с производителем хранилища, поддерживает ли он такую конфигурацию.
Выведенные из эксплуатации технологии
Устаревание NPIV
Как VMware предупреждала ранее, технология N-Port ID Virtualization (NPIV) была признана устаревшей и в версии 9.0 больше не поддерживается.
Устаревание гибридной конфигурации в оригинальной архитектуре хранения vSAN (OSA)
Гибридная конфигурация в vSAN Original Storage Architecture будет удалена в одном из будущих выпусков платформы VCF.
Устаревание поддержки vSAN over RDMA
Поддержка vSAN поверх RDMA для архитектуры vSAN OSA также будет прекращена в будущем выпуске VCF.
Устаревание поддержки RVC и зависимых Ruby-компонентов
Начиная с версии VCF 9.0, Ruby vSphere Console (RVC) и её компоненты на базе Ruby (такие как Rbvmomi) в составе vCenter считаются устаревшими. RVC, ранее использовавшаяся технической поддержкой для тестирования и мониторинга систем, уже была признана устаревшей, начиная с vSAN 7.0.
Для задач мониторинга и сопровождения Broadcom рекомендует использовать PowerCLI, DCLI или веб-интерфейс vCenter (UI), поскольку они теперь предоставляют весь функционал, ранее доступный в RVC. RVC и все связанные с ней Ruby-компоненты будут окончательно удалены в одном из будущих выпусков VCF.
В стремительно меняющемся ИТ-ландшафте современности организации сталкиваются с совокупностью тенденций, которые меняют их подход к инфраструктуре — особенно к хранилищам данных. VMware Cloud Foundation (VCF) 9.0 предлагает серьёзные усовершенствования в VMware vSAN 9, соответствующие этим тенденциям и позволяющие предприятиям эффективно, производительно и надёжно удовлетворять современные потребности в хранении данных.
Тенденции отрасли и вызовы для клиентов
Предприятия сталкиваются с быстрыми изменениями как в датацентрах, так и на рынке, и всё чаще становится ясно, что существующие подходы не справляются с новыми задачами — цифровая трансформация становится необходимостью.
Первая ключевая тенденция — рост объёма данных. Данные давно называют «цифровым золотом», ведь они дают конкурентное преимущество за счёт аналитики, новых продуктов и услуг. В дата-центрах особенно быстро растёт объём неструктурированных данных, и общий рост объёма информации остаётся высоким. Стоимость хранения и удержания этих данных — одна из главных проблем. ИТ-отделам необходимы технологии повышения эффективности хранения, такие как дедупликация и сжатие, чтобы снизить совокупную стоимость владения (TCO). Также им нужны хранилища большой ёмкости с низкой задержкой, которые сочетают в себе экономичность и производительность, необходимую для приложений, работающих с этими данными.
Меняется и способ доступа приложений к данным. В организациях стремительно внедряются новые интерфейсы хранения, с помощью которых данные превращаются в источники дохода. Для удовлетворения этих требований предприятия обращаются к объектному хранилищу и высокопроизводительным файловым системам как к основным интерфейсам, особенно для AI-нагрузок. Такие задачи требуют также гибкого управления данными, чтобы обеспечить точность моделей AI и снизить задержки. Сегодня ИТ-отделы используют точечные решения под каждый тип данных, но им гораздо удобнее было бы иметь унифицированную платформу, обеспечивающую простое управление и быструю работу.
Инфраструктурная фрагментация и гибридное облако
Рост объёма данных и внедрение новых интерфейсов усугубляется фрагментацией инфраструктуры, вызванной активным переходом к гибридным облачным стратегиям. По недавнему исследованию компании Broadcom, 92% организаций используют смесь частных и публичных облаков. Это означает, что данные и рабочие нагрузки распределены между локальными датацентрами, периферийными (edge) точками и публичными облаками. В результате появляется множество уникальных архитектур на базе точечных решений, которые трудно масштабировать и поддерживать. ИТ-отделам нужен единый подход к хранению данных и операциям с ними во всех средах, чтобы снизить сложность.
Какие рабочие нагрузки вызывают этот рост данных и требуют новых интерфейсов?
AI-задачи предъявляют совершенно новые требования к инфраструктуре хранения. Как прогнозирующий AI (уже широко используемый), так и генеративный AI (стремительно набирающий популярность) зависят от быстрого и надёжного доступа к огромным объёмам данных. Даже такие специфические рабочие нагрузки, как RAG (Retrieval Augmented Generation), нуждаются в хранилищах с высокой производительностью и низкой задержкой — гораздо выше, чем у традиционных систем на жёстких дисках, где сейчас хранятся многие AI-данные. Более того, AI-среды требуют прямого, высокоскоростного доступа к хранилищам с GPU, в обход узких мест, связанных с CPU, чтобы обрабатывать данные с минимальной задержкой.
Контейнеры, хранилище и скорость разработки
Хотя многие приложения по-прежнему работают в виртуальных машинах, использование контейнеров растёт, особенно в AI-сценариях. Контейнеры по своей природе эфемерны, но используемое ими хранилище должно быть постоянным и отделённым от жизненного цикла контейнера. По мере роста количества контейнеров, управление хранилищем должно происходить на более детализированном уровне — часто на уровне отдельного тома — и быть тесно интегрировано с системой оркестрации контейнеров для быстрой разработки.
В итоге ИТ-отделам необходимы программно-определяемые хранилища, которые масштабируются так же быстро, как контейнеры, и которые можно управлять теми же инструментами и с той же точностью, что и виртуальными машинами. Плюс, они должны предоставлять разработчикам быстрый доступ к инфраструктуре через привычные им инструменты, чтобы ускорить вывод продуктов на рынок.
Устойчивость к киберугрозам
Наконец, киберустойчивость остаётся в приоритете. Программы-вымогатели (ransomware) по-прежнему представляют серьёзную угрозу: в 2023 году две трети организаций подверглись атакам, и более 75% таких случаев сопровождались шифрованием данных. Кибербезопасность регулярно занимает первые места среди главных проблем CIO.
Стратегия хранения данных VMware и современные решения
Видение VMware в области хранения данных в рамках VMware Cloud Foundation заключается в предоставлении полностью интегрированных, унифицированных возможностей хранения в составе программно-определяемого частного облака, охватывающего локальные, периферийные (edge), публичные и суверенные облачные среды. Cтратегия VMware направлена на создание единой, универсальной платформы хранения, поддерживающей как первичные, так и вторичные сценарии использования для различных типов данных и рабочих нагрузок. Эта платформа создаётся с целью упростить операции, повысить безопасность, сократить затраты и ускорить инновации.
Снижение стоимости хранения
VMware уделяет особое внимание снижению затрат, что особенно важно для клиентов. VMware Cloud Foundation включает 1 TiB хранилища vSAN на одно ядро в своей лицензионной модели, что позволило клиентам сократить среднюю стоимость хранения на 30%, а в отдельных случаях — снизить TCO более чем на 40% по сравнению с традиционными массивами с контроллерами.
Дополнительно, VMware снижает расходы за счёт поддержки сертифицированных стандартных серверов: более 500 конфигураций vSAN ReadyNode от 15 OEM-производителей. Это в среднем снижает стоимость хранения на 46% за терабайт. Масштабируемая гиперконвергентная архитектура устраняет неиспользуемую ёмкость, типичную для масштабируемых систем (scale-up), а серверный подход позволяет существенно сократить затраты на поддержку и управление. В итоге заказчики получают высокопроизводительное, устойчивое хранилище для критически важных задач — без высокой стоимости устаревших решений.
С выпуском VCF 9.0 VMware представила глобальную дедупликацию на программном уровне, которая позволяет дополнительно сократить объём хранимых данных вплоть до 8 раз, что особенно актуально при росте объёма информации.
Новая дедупликация vSAN:
Имеет минимальную нагрузку на CPU
Работает в фоновом режиме, когда системные ресурсы не загружены
Охватывает все данные в кластере, а не только данные за одним контроллером, как в традиционных системах
Масштабируется вместе с кластером, что даёт более высокую эффективность
В будущем VMware планирует дополнительно снижать стоимость хранения за счёт более плотных носителей, соответствующих жёстким требованиям по производительности и задержкам. Совместно с гибкой лицензионной моделью это откроет новые сценарии использования vSAN, включая вторичное хранилище для резервного копирования.
Хранилище с низкой задержкой для AI-нагрузок
AI-задачи предъявляют повышенные требования к инфраструктуре, и vSAN соответствует этим требованиям благодаря архитектуре Express Storage Architecture (ESA) нового поколения. На сегодняшний день vSAN ESA обеспечивает:
До 300 000 IOPS на узел.
Постоянную задержку менее 1 мс, даже при пиковых нагрузках.
Линейный рост производительности и ёмкости по мере масштабирования кластера — в отличие от традиционного хранилища, где масштабируется только ёмкость.
Гибкость при сбоях: недавние тесты показали на 60% меньшую задержку в аварийных сценариях по сравнению с классическими системами.
В текущем релизе VMware повысила производительность кластеров vSAN до 25% за счёт разделения трафика — теперь можно использовать отдельные сети для вычислений и хранилища. Это не только освобождает пропускную способность для хранилища, но и позволяет использовать существующие инвестиции. Клиенты могут выбрать более дешёвую, низкоскоростную сеть для вычислений, не тратясь на дорогостоящую высокоскоростную сеть для совместного использования вычислительных и хранилищных задач.
В будущем VMware планирует расширить хранилище vSAN с низкими задержками на вторичные сценарии, включая предиктивные и генеративные AI-нагрузки. vSAN будет обладать оптимальным сочетанием высокой ёмкости, низкой задержки и масштабируемости, чтобы точно соответствовать требованиям этих задач.
Программно-определяемое хранилище для любых рабочих нагрузок
VMware vSAN предлагает гибкую, программно-определяемую, масштабируемую архитектуру, позволяющую организациям оптимизировать и расширять объём хранилища по мере необходимости. Клиенты могут масштабироваться линейно или раздельно, начиная с малого и доходя до петабайтового уровня.
С помощью драйвера CSI vSAN поддерживает постоянные тома для контейнерных нагрузок, позволяя разработчикам работать с инфраструктурой VMware через привычные инструменты. Администраторы получают гранулированный контроль и видимость томов контейнеров, воспринимая их как полноправные элементы инфраструктуры. Поскольку vSAN полностью интегрирован с CSI-драйвером, контейнеры могут использовать управление на основе политик хранения, обеспечивая быстрое и масштабируемое развертывание.
Автоматизация VCF
VCF Automation (VCF-A) в VCF 9.0 предоставляет простой способ предоставления томов для различных арендаторов, использующих хранилище как для ВМ, так и для постоянных томов в Kubernetes-среде VMware (VKS).
В будущем VMware планирует развивать многопользовательские сценарии и инфраструктуру как услугу (IaaS), чтобы дать разработчикам быстрый доступ к ресурсам при сохранении корпоративного контроля.
Единая модель управления хранилищем для локальных, периферийных и облачных сред
Для обеспечения последовательности в операциях VMware Cloud Foundation предлагает унифицированную программно-определяемую инфраструктуру во всех средах VMware — в датацентрах, на периферии и в облаках.
VMware сотрудничает с широчайшим кругом облачных партнёров (все крупные гиперскейлеры и сотни региональных провайдеров), чтобы обеспечить единообразный пользовательский опыт, включая управление хранилищем, во всех типах облаков.
VCF 9.0 включает важные инновации в управлении хранилищем:
Автоматическое развертывание, масштабирование и обновление инфраструктуры на базе vSAN
Единая консоль для всей VCF-инфраструктуры (vSAN, VMFS, NFS)
Уведомления о состоянии, рекомендации и пошаговое устранение проблем
Поддержка мультисайтовых сред для единого мониторинга.
В ближайшее время облачные партнёры внедрят vSAN ESA (Express Storage Architecture) в свои стеки VCF: VMware Cloud Foundation на AWS, Google Cloud VMware Engine и Azure VMware Solution добавят поддержку ESA.
В рамках этой стратегии технология vVols будет выведена из эксплуатации, начиная с VCF/VVF 9.0, и полностью отключена в будущих релизах. vVols не обеспечивают единый операционный подход между локальными, edge и облачными средами, так как не были внедрены большинством публичных и суверенных облачных партнёров.
Их распространённость остаётся низкой (единицы процентов), и они остаются нишевым решением. VMware по-прежнему будет поддерживать внешние хранилища через VMFS и NFS.
Безопасность и киберустойчивость для частного облака
Безопасность и устойчивость — основа vSAN, особенно важная для пользователей VCF. С выпуском vSAN 8.0 появилась новая система моментальных снимков (снапшотов), а в vSAN 8 Update 3 — встроенная защита данных, позволяющая администраторам легко защищать ВМ от случайных или вредоносных действий (например, удаления или атак программ-вымогателей).
Это реализуется через группы защиты, где можно задать, что защищать, как часто и как долго, с поддержкой неизменяемых снапшотов и шифрованием (FIPS 140-3) как для хранимых, так и передаваемых данных.
В VCF 9.0 добавлена репликация vSAN-to-vSAN, основанная на защите данных vSAN. Она позволяет удалённо реплицировать снапшоты на любое хранилище vSAN ESA — как гиперконвергентное, так и разнесённое.
Эта асинхронная репликация:
Дешевле и быстрее традиционной массивной репликации
Позволяет восстанавливать отдельные ВМ, а не целые LUN
Требует меньше места и меньше трафика
Значительно упрощает восстановление, переключение и возврат свободного места
Также репликация интегрирована с VMware Live Recovery (VLR) для восстановления после кибератак и аварий. VCF 9.0 поддерживает кибервосстановление в изолированную зону внутри локального VCF, что важно для соблюдения требований суверенитета и конфиденциальности данных.
Интеграция vSAN и VLR позволяет хранить длинную историю снапшотов, что критично при атаке с шифрованием, когда приходится откатываться назад до "чистых" копий. Управление и кибервосстановление, и аварийным восстановлением возможно через один VLR-апплаенс, с масштабированием восстановления с помощью кластеров vSAN.
В перспективе будет реализована функция Intelligent Threat Detection — AI/ML-алгоритмы для превентивной защиты, раннего обнаружения и анализа зашифрованных копий.
Унифицированное хранилище для всех типов данных
Клиенты давно хотят единую платформу хранения для всех задач, а не отдельные решения для блочного, файлового и объектного хранилища, что создаёт избыточную сложность. vSAN изначально предлагает блочное хранилище, а с 2019 года — встроенные файловые сервисы. VCF 9.0 расширяет их масштабируемость: теперь до 500 файловых ресурсов на кластер.
В будущем планируется добавление новых встроенных протоколов, ориентированных на высокую пропускную способность и низкую задержку, необходимых для AI-задач.
Взгляд в будущее
VMware vSAN — это интегрированное хранилище для частных облаков, на которое предприятия полагаются при работе с критически важными приложениями. Оно помогает сократить капитальные и операционные издержки, обеспечивая при этом производительность, масштаб и устойчивость, необходимые для современных нагрузок — от облачных приложений до AI-аналитики.
Благодаря единым операциям во всех средах (edge, core, облако) и ведущим в отрасли возможностям киберустойчивости, vSAN становится фундаментом современного частного облака.
VMware продолжает инвестировать в инновации, чтобы:
ROSA Virtualization — это отечественная платформа для управления виртуальной серверной инфраструктурой, разработанная АО «НТЦ ИТ РОСА». Она построена на базе открытого программного обеспечения (KVM, libvirt и др.) и предназначена для развёртывания отказоустойчивых, масштабируемых и защищённых виртуализованных сред.
Основные функции платформы:
Создание и управление виртуальными машинами
Настройка виртуальных сетей и хранилищ
Кластеры высокой доступности (HA)
Живая миграция ВМ между хостами
Резервное копирование и восстановление
Централизованное управление через веб-интерфейс
Поддержка требований по безопасности и соответствие ГОСТ
Сертификация для использования в госорганах
Главные изменения ROSA Virtualization 3.1 (релиз 27 мая 2025 года)
1. Отказ от CLI — весь функционал в GUI
Теперь все операции, включая настройку LDAP, шифрование дисков и управление пользователями, доступны через единый графический интерфейс. CLI используется только в самых экстренных случаях.
2. Поддержка Ceph
Включение интеграции с распределённым хранилищем Ceph позволило значительно повысить отказоустойчивость, масштабируемость и надёжность платформы.
3. Живая миграция ВМ и автозапуск
Поддерживается безостановочная миграция виртуальных машин между кластерами. Кроме того, при корректной перезагрузке хоста ВМ теперь автоматически запускаются после восстановления.
4. Сеть, визуализация и резервное копирование
Добавлена визуализация сетевой схемы, мастер настройки NFS, улучшен интерфейс бэкапов (включительно поддержка СУСВ через веб), а также адаптация событий под требования ГОСТ.
5. Интеграция с Loudplay и безопасность
Нововведения включают поддержку Loudplay (протокол для передачи консольных данных) и адаптацию событийной логики в соответствии с ГОСТ-стандартами.
6. Лицензирование и сертификация
Платформа доступна по одной из двух моделей лицензирования: либо по числу виртуальных машин, либо по числу хостов. В комплект входит год технической поддержки, включая версию сертифицированную ФСТЭК.
Почему это важно
Упрощение управления: привычные интерфейсы GUI значительно снижают порог входа для операторов и системных администраторов.
Надёжность и масштабируемость: интеграция с Ceph обеспечивает отказоустойчивую, распределённую архитектуру хранения.
Бесшовность и доступность: живая миграция и автозапуск ВМ минимизируют время простоя.
Безопасность и соответствие: ГОСТ-адаптация и сертификация ФСТЭК делают решение готовым к внедрению в государственных структурах и критически важной инфраструктуре.
Кому подойдёт ROSA Virtualization 3.1
Организациям госсектора и тем, кто выполняет требования по импортозамещению и ГОСТ-сертификации.
Компаниям, нуждающимся в простом и визуальном администрировании виртуальной инфраструктуры.
Телеком-операторам, дата-центрам и частным компаниям, которым важна отказоустойчивость и масштабируемость.
ROSA Virtualization 3.1 — зрелое отечественное решение для виртуализации, сочетающее:
Простоту и удобство графического интерфейса
Корпоративную надёжность благодаря Ceph и живой миграции
Соответствие государственным стандартам безопасности.
Платформа отлично подходит для предприятий и госструктур, где нужна надёжная, масштабируемая и управляемая виртуальная инфраструктура отечественного производства.
Продолжаем рассказывать о российском ПО в сфере серверной виртуализации. Numa vServer — российская платформа серверной виртуализации корпоративного уровня, разработанная компанией «НумаТех». Она предназначена для создания защищённых виртуальных инфраструктур и соответствует требованиям информационной безопасности, установленным ФСТЭК России.
Архитектура и технологии
В основе Numa vServer лежит гипервизор первого типа на базе Xen, доработанный более чем в 300 аспектах для повышения безопасности, надёжности и производительности. Платформа устанавливается напрямую на аппаратное обеспечение (bare-metal), что исключает необходимость в хостовой операционной системе и обеспечивает высокую производительность и безопасность.
Безопасность и сертификация
Numa vServer сертифицирован ФСТЭК России по 4 уровню доверия и 4 классу защиты (сертификат № 4580 от 23.09.2022) . Это позволяет использовать платформу в государственных информационных системах, системах обработки персональных данных, АСУ ТП и критически важных объектах.
Ключевые функции безопасности:
Изолированная среда исполнения управляющей ВМ (Domain 0).
Мандатный контроль доступа и зонирование.
Контроль целостности конфигураций, журналов и образов ВМ.
Журналирование действий пользователей и фильтрация потоков данных.
Поддержка многофакторной аутентификации и интеграция с LDAP/Active Directory.
Функциональные возможности
Кластеризация и высокая доступность: поддержка до 64 серверов в одном пуле с возможностью автоматической миграции ВМ при сбоях.
Резервное копирование и восстановление: полные и дельта-копии, снэпшоты, репликация, поддержка протоколов NFS, SMB/CIFS, S3.
Импорт/экспорт ВМ: поддержка форматов VMware, Citrix, VirtualBox.
Управление через Numa Collider: веб-интерфейс для администрирования, мониторинга и настройки виртуальной инфраструктуры.
Интеграция с OpenStack и CloudStack: поддержка инструментов IaC, таких как Packer и Terraform.
Виртуализация GPU: возможность делить графический адаптер между несколькими ВМ с поддержкой 3D-графики.
Системные требования
Numa vServer предъявляет низкие требования к оборудованию, что позволяет использовать его на серверах возрастом более 10 лет.
Минимальные требования:
Процессор: 2 ядра, 1.5 ГГц.
Оперативная память: 4 ГБ.
Диск: 128 ГБ.
Сетевой адаптер: 1 порт, 100 Мбит/с.
Рекомендуемые характеристики:
Процессор: 4–8 ядер, 2.5 ГГц с поддержкой Intel-VT или AMD-V.
Оперативная память: 16 ГБ с поддержкой ECC.
Диск: 750 ГБ.
Сетевой адаптер: 2 порта, 1 Гбит/с.
Лицензирование и поддержка
Лицензирование Numa vServer осуществляется по количеству физических процессоров. В базовую лицензию входит редакция «Начальная» консоли управления Numa Collider. Доступны также расширенные редакции с дополнительным функционалом, такими как балансировка нагрузки, программно-определяемые сети и расширенные возможности резервного копирования.
Применение и преимущества
Numa vServer подходит для организаций, стремящихся к импортозамещению и обеспечению информационной безопасности. Платформа может использоваться для:
Создания защищённых частных, публичных или гибридных облаков.
Виртуализации отдельных серверных ролей.
Обеспечения высокой доступности критически важных систем.
Выполнения требований регуляторов в области защиты информации.
Преимущества:
Быстрое развёртывание и простота эксплуатации.
Высокий уровень безопасности и соответствие требованиям ФСТЭК.
Низкие системные требования и возможность использования на устаревшем оборудовании.
Гибкая модель лицензирования и конкурентная стоимость владения.
Заключение
Numa vServer представляет собой надёжное и функциональное решение для создания защищённых виртуальных инфраструктур в условиях импортозамещения. Благодаря своей архитектуре, соответствию требованиям безопасности и широкому функционалу, платформа может стать основой для построения эффективных и безопасных ИТ-систем в различных отраслях.
В данной статье описывается, как развернуть дома полноценную лабораторию VMware Cloud Foundation (VCF) на одном физическом компьютере. Мы рассмотрим выбор оптимального оборудования, поэтапную установку всех компонентов VCF (включая ESXi, vCenter, NSX, vSAN и SDDC Manager), разберем архитектуру и взаимодействие компонентов, поделимся лучшими практиками...
Интересный пост, касающийся использования виртуальных хранилищ NFS (в формате Virtual Appliance) на платформе vSphere и их производительности, опубликовал Marco Baaijen в своем блоге. До недавнего времени он использовал центральное хранилище Synology на основе NFSv3 и две локально подключенные PCI флэш-карты. Однако из-за ограничений драйверов он был вынужден использовать ESXi 6.7 на одном физическом хосте (HP DL380 Gen9). Желание перейти на vSphere 8.0 U3 для изучения mac-learning привело тому, что он больше не мог использовать флэш-накопители в качестве локального хранилища для размещения вложенных виртуальных машин. Поэтому Марко решил использовать эти флэш-накопители на отдельном физическом хосте на базе ESXi 6.7 (HP DL380 G7).
Теперь у нас есть хост ESXi 8 и и хост с версией ESXi 6.7, которые поддерживают работу с этими флэш-картами. Кроме того, мы будем использовать 10-гигабитные сетевые карты (NIC) на обоих хостах, подключив порты напрямую. Марко начал искать бесплатное, удобное и функциональное виртуальное NAS-решение. Рассматривал Unraid (не бесплатный), TrueNAS (нестабильный), OpenFiler/XigmaNAS (не тестировался) и в итоге остановился на OpenMediaVault (с некоторыми плагинами).
И вот тут начинается самое интересное. Как максимально эффективно использовать доступное физическое и виртуальное оборудование? По его мнению, чтение и запись должны происходить одновременно на всех дисках, а трафик — распределяться по всем доступным каналам. Он решил использовать несколько паравиртуальных SCSI-контроллеров и настроить прямой доступ (pass-thru) к портам 10-гигабитных NIC. Всё доступное пространство флэш-накопителей представляется виртуальной машине как жесткий диск и назначается по круговому принципу на доступные SCSI-контроллеры.
В OpenMediaVault мы используем плагин Multiple-device для создания страйпа (striped volume) на всех доступных дисках.
На основе этого мы можем создать файловую систему и общую папку, которые в конечном итоге будут представлены как экспорт NFS (v3/v4.1). После тестирования стало очевидно, что XFS лучше всего подходит для виртуальных нагрузок. Для NFS Марко решил использовать опции async и no_subtree_check, чтобы немного увеличить скорость работы.
Теперь переходим к сетевой части, где автор стремился использовать оба 10-гигабитных порта сетевых карт (X-соединённых между физическими хостами). Для этого он настроил следующее в OpenMediaVault:
С этими настройками серверная часть NFS уже работает. Что касается клиентской стороны, Марко хотел использовать несколько сетевых карт (NIC) и порты vmkernel, желательно на выделенных сетевых стэках (Netstacks). Однако, начиная с ESXi 8.0, VMware решила отказаться от возможности направлять трафик NFS через выделенные сетевые стэки. Ранее для этого необходимо было создать новые стэки и настроить SunRPC для их использования. В ESXi 8.0+ команды SunRPC больше не работают, так как новая реализация проверяет использование только Default Netstack.
Таким образом, остаётся использовать возможности NFS 4.1 для работы с несколькими соединениями (parallel NFS) и выделения трафика для портов vmkernel. Но сначала давайте посмотрим на конфигурацию виртуального коммутатора на стороне NFS-клиента. Как показано на рисунке ниже, мы создали два раздельных пути, каждый из которых использует выделенный vmkernel-порт и собственный физический uplink-NIC.
Первое, что нужно проверить, — это подключение между адресами клиента и сервера. Существуют три способа сделать это: от простого до более детального.
[root@mgmt01:~] esxcli network ip interface list
---
vmk1
Name: vmk1
MAC Address: 00:50:56:68:4c:f3
Enabled: true
Portset: vSwitch1
Portgroup: vmk1-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 134217815
vmk2
Name: vmk2
MAC Address: 00:50:56:6f:d0:15
Enabled: true
Portset: vSwitch2
Portgroup: vmk2-NFS
Netstack Instance: defaultTcpipStack
VDS Name: N/A
VDS UUID: N/A
VDS Port: N/A
VDS Connection: -1
Opaque Network ID: N/A
Opaque Network Type: N/A
External ID: N/A
MTU: 9000
TSO MSS: 65535
RXDispQueue Size: 4
Port ID: 167772315
[root@mgmt01:~] esxcli network ip netstack list defaultTcpipStack
Key: defaultTcpipStack
Name: defaultTcpipStack
State: 4660
[root@mgmt01:~] ping 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.219 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.173 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.174 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.173/0.189/0.219 ms
[root@mgmt01:~] ping 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.155 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.141 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.187 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.161/0.187 ms
root@mgmt01:~] vmkping -I vmk1 10.10.10.62
PING 10.10.10.62 (10.10.10.62): 56 data bytes
64 bytes from 10.10.10.62: icmp_seq=0 ttl=64 time=0.141 ms
64 bytes from 10.10.10.62: icmp_seq=1 ttl=64 time=0.981 ms
64 bytes from 10.10.10.62: icmp_seq=2 ttl=64 time=0.183 ms
--- 10.10.10.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.141/0.435/0.981 ms
[root@mgmt01:~] vmkping -I vmk2 172.16.0.62
PING 172.16.0.62 (172.16.0.62): 56 data bytes
64 bytes from 172.16.0.62: icmp_seq=0 ttl=64 time=0.131 ms
64 bytes from 172.16.0.62: icmp_seq=1 ttl=64 time=0.187 ms
64 bytes from 172.16.0.62: icmp_seq=2 ttl=64 time=0.190 ms
--- 172.16.0.62 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.131/0.169/0.190 ms
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk1 -H 10.10.10.62
Trace:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 139 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 180 us
Dup: false
Detail:
Received Bytes: 64
Host: 10.10.10.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 148 us
Dup: false
Detail:
Summary:
Host Addr: 10.10.10.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 139 us
Round-trip Avg: 155 us
Round-trip Max: 180 us
[root@mgmt01:~] esxcli network diag ping --netstack defaultTcpipStack -I vmk2 -H 172.16.0.62
Trace:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 0
TTL: 64
Round-trip Time: 182 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 1
TTL: 64
Round-trip Time: 136 us
Dup: false
Detail:
Received Bytes: 64
Host: 172.16.0.62
ICMP Seq: 2
TTL: 64
Round-trip Time: 213 us
Dup: false
Detail:
Summary:
Host Addr: 172.16.0.62
Transmitted: 3
Received: 3
Duplicated: 0
Packet Lost: 0
Round-trip Min: 136 us
Round-trip Avg: 177 us
Round-trip Max: 213 us
С этими положительными результатами мы теперь можем подключить NFS-ресурс, используя несколько подключений на основе vmk, и убедиться, что всё прошло успешно.
Наконец, мы проверяем, что оба подключения действительно используются, доступ к дискам осуществляется равномерно, а производительность соответствует ожиданиям (в данном тесте использовалась миграция одной виртуальной машины с помощью SvMotion). На стороне NAS-сервера Марко установил net-tools и iptraf-ng для создания приведённых ниже скриншотов с данными в реальном времени. Для анализа производительности флэш-дисков на физическом хосте использовался esxtop.
root@openNAS:~# netstat | grep nfs
tcp 0 128 172.16.0.62:nfs 172.16.0.60:623 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:617 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:616 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:621 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:613 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:620 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:610 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:611 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:615 ESTABLISHED
tcp 0 128 172.16.0.62:nfs 172.16.0.60:619 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:609 ESTABLISHED
tcp 0 128 10.10.10.62:nfs 10.10.10.60:614 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:618 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:622 ESTABLISHED
tcp 0 0 172.16.0.62:nfs 172.16.0.60:624 ESTABLISHED
tcp 0 0 10.10.10.62:nfs 10.10.10.60:612 ESTABLISHED
По итогам тестирования NFS на ESXi 8 Марко делает следующие выводы:
NFSv4.1 превосходит NFSv3 по производительности в 2 раза.
XFS превосходит EXT4 по производительности в 3 раза (ZFS также был протестирован на TrueNAS и показал отличные результаты при последовательных операциях ввода-вывода).
Клиент NFSv4.1 в ESXi 8.0+ не может быть привязан к выделенному/отдельному сетевому стэку (Netstack).
Использование нескольких подключений NFSv4.1 на основе выделенных портов vmkernel работает очень эффективно.
Виртуальные NAS-устройства демонстрируют хорошую производительность, но не все из них стабильны (проблемы с потерей NFS-томов, сообщения об ухудшении производительности NFS, увеличении задержек ввода-вывода).
На портале технических ресурсов Broadcom появилась полезная статья, посвященная производительности облачных приложений и причинам их земедления в производственной среде.
Часто бывает, что приложение, работающее на физическом сервере, демонстрирует хорошую производительность. Однако после упаковки приложения в образ, тестирования в Docker/Podman и последующей миграции в окружение Kubernetes производительность резко падает. По мере увеличения числа запросов к базе данных, выполняемых приложением, время отклика приложения возрастает.
Эта распространённая ситуация часто вызвана задержками ввода-вывода, связанными с передачей данных. Представьте, что это же приложение снова запускается на физическом сервере, но в следующем сценарии: устройство хранения базы данных создаётся на удалённом хранилище с Network File System (NFS).
Это означает, что необходимо учитывать следующие факторы:
Количество приложений, обращающихся к конечной точке хранилища (предполагается, что оно быстрое по своему устройству).
Это будет влиять на общую производительность отклика из-за производительности подсистемы ввода-вывода хранилища.
Способ, которым приложение извлекает данные из базы данных.
Кэширует ли оно данные, или просто отправляет очередной запрос? Являются ли запросы небольшими или крупными?
Задержка, вызванная сетевым доступом к хранилищу, и общая скорость работы хранилища.
При доступе к сетевому устройству несколько ключевых факторов влияют на скорость передачи данных:
Доступная скорость соединения
Используемое максимальное время передачи (MTU) / максимальный размер сегмента (MSS)
Размер передаваемой полезной нагрузки
Настройки TCP окна (скользящее окно)
Среднее время задержки при прохождении маршрута (RTT) от точки A до точки B в мс.
В датацентре скорость соединения обычно не является проблемой, поскольку все узлы соединены с пропускной способностью не менее 1 Гбит/с, иногда 10 Гбит/с, и подключены к одному коммутатору. MTU/MSS будет оптимальным для настроенного соединения. Остаются размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT. Наибольшее влияние окажут размер полезной нагрузки, задержка соединения и его качество, которые будут влиять на параметры скользящего окна.
Вот пример задержек между узлами в текущей настройке Kubernetes:
При увеличении размера полезной нагрузки пакета в пинге, как только он превышает текущий MTU, время отклика начинает увеличиваться. Например, для node2 размер полезной нагрузки составляет 64k — это экстремальный случай, который наглядно демонстрирует рост задержки.
Учитывая эти три момента (размер передаваемой полезной нагрузки, скользящее окно TCP и среднее RTT), если разработчик создаёт приложение без использования встроенных возможностей кэширования, то запросы к базе данных начнут накапливаться, вызывая нагрузку на ввод-вывод. Такое упущение направляет все запросы через сетевое соединение, что приводит к увеличению времени отклика всего приложения.
На локальном хранилище или в среде с низкой задержкой (как сети, так и хранилища) можно ожидать, что приложение будет работать хорошо. Это типичная ситуация, когда команды разработки тестируют все в локальной среде. Однако при переходе на сетевое хранилище задержка, вызванная сетью, будет влиять на возможный максимальный уровень запросов. При проведении тех же тестов в производственной среде команды, вероятно, обнаружат, что система, способная обрабатывать, скажем, 1000 запросов к базе данных в секунду, теперь справляется только с 50 запросами в секунду. В таком случае стоит обратить внимание на три вероятные причины:
Переменные размеры пакетов, средний размер которых превышает настроенный MTU.
Сетевая задержка из-за того, что база данных размещена на отдельном узле, вдали от приложения.
Уменьшенное скользящее окно, так как все связанные системы подключаются к узлу базы данных. Это создаёт нагрузку на ввод-вывод файловой системы, из-за чего база данных не может обрабатывать запросы достаточно быстро.
Тесты показали, что алгоритм скользящего окна привёл к снижению скорости передачи данных (для справки: это механизм, используемый удалённым хранилищем на основе NFS). При среднем размере полезной нагрузки 4 Кб скорость передачи данных упала с 12 МБ/с на быстром соединении 1 Гбит/с (8 мс задержки) до ~15 Кбит/с, когда задержка соединения достигла 180 мс. Скользящее окно может вынудить каждую передачу данных возвращать пакет подтверждения (ACK) отправителю перед отправкой следующего пакета на соединениях с низкой задержкой.
Эту ситуацию можно протестировать локально с помощью утилиты tc на системе Linux. С её помощью можно вручную задать задержку для каждого устройства. Например, интерфейс можно настроить так, чтобы он отвечал с задержкой в 150 мс.
На Kubernetes, например, вы можете развернуть приложение с фронтендом, сервером приложений и бэкендом базы данных. Если сервер приложений и бэкенд базы данных развернуты на разных узлах, даже если эти узлы быстрые, они будут создавать сетевые задержки для каждого пакета, отправленного с сервера приложений в базу данных и обратно. Эти задержки суммируются и значительно ухудшают производительность!
Ниже приведён реальный пример, показывающий время отклика приложения. База данных развернута на node2.
В этом случае выполнение приложения требует большого количества запросов к базе данных, что значительно влияет на среднее время отклика затронутых компонентов. В данном случае среднее время отклика составляет 3,9 секунды.
Для этого теста функция graph_dyn запрашивает из базы данных 80 тысяч строк данных, где каждая строка содержит метаданные для построения различных точек графика.
Переместив базу данных на ту же машину, где размещена часть приложения, удалось снизить среднее время отклика до 0,998 секунды!
Это значительное улучшение производительности было достигнуто за счёт сокращения задержек сетевых запросов (round trip), то есть перемещения контейнера базы данных на тот же узел.
Ещё одним распространённым фактором, влияющим на производительность Kubernetes, являются ESXi-среды, где узлы кластера имеют избыточную нагрузку на ввод-вывод сети, а узлы Kubernetes развёрнуты в виде виртуальных машин. Узел Kubernetes не может увидеть, что CPU, память, ввод-вывод диска и/или подключённое удалённое хранилище уже находятся под нагрузкой. В результате пользователи сталкиваются с ухудшением времени отклика приложений.
Как оптимизировать производительность приложения
Учтите кэширование в дизайне приложения.
Убедитесь, что приложение учитывает кэширование (общих запросов, запросов к базе данных и так далее) и не выполняет лишних запросов.
Отключите переподписку ресурсов (oversubscription) в средах ESXi.
Если Kubernetes/OpenShift работают поверх ESXi, убедитесь, что переподписка ресурсов отключена для всех доступных CPU и памяти. Учтите, что даже небольшие задержки могут быстро накопиться и привести к эластичному поведению времени отклика приложения. Кроме того, если хост ESXi уже находится под нагрузкой, запущенные на нём образы не будут осведомлены об этом, и оркестратор Kubernetes может развернуть дополнительные поды на этом узле, считая ресурсы (CPU, память, хранилище) всё ещё доступными. Поэтому, если вы используете Kubernetes/OpenShift, а у вас есть возможность запустить их на физическом сервере, сделайте это! Вы получите прямую и полную видимость ресурсов хоста.
Минимизируйте сетевые задержки ввода-вывода в Kubernetes.
Сократите сетевые задержки ввода-вывода при развёртывании подов. Упакуйте контейнеры в один под, чтобы они развертывались на одном узле. Это значительно снизит сетевые задержки ввода-вывода между сервером приложений и базой данных.
Размещайте контейнеры с высокими требованиями к базе данных на узлах с быстрым хранилищем.
Развёртывайте контейнеры, которым требуется быстрый доступ к базе данных, на узлах с быстрым хранилищем. Учитывайте требования к высокой доступности и балансировке нагрузки. Если хранилище NFS недостаточно быстрое, рассмотрите возможность создания PV (Persistent Volume) на определённом узле с локальным RAID 10 диском. Учтите, что в этом случае резервирование придётся настраивать вручную, так как оркестратор Kubernetes не сможет управлять этим при отказе оборудования конкретного узла.
Как мониторить задержки между компонентами
Для Kubernetes, OpenShift и Docker (Swarm) можно использовать Universal Monitoring Agent (UMA), входящий в решения AIOps and Observability от Broadcom, для мониторинга взаимодействия всего окружения. Этот агент способен извлекать все релевантные метрики кластера. Если UMA обнаруживает поддерживаемую технологию, такую как Java, .Net, PHP или Node.js, он автоматически внедряет пробу (probe) и предоставляет детализированную информацию о выполнении приложения по запросу. Эти данные включают запросы ввода-вывода (I/O) от компонента к базе данных, удалённые вызовы и другие внутренние метрики приложения.
Если приложение работает некорректно, встроенное обнаружение аномалий UMA запускает трассировку транзакций (это не требует дополнительной настройки). UMA собирает подробные метрики с агентов, связанных с компонентами, по пути выполнения конкретного приложения. Эти возможности позволяют получить детализированное представление выполнения приложения вплоть до строки кода, вызывающей замедление. Администраторы могут настроить полный сквозной мониторинг, который предоставляет детали выполнения, включая производительность фронтенда (браузера).
Ниже приведен пример сбора полных сквозных метрик, чтобы команда администраторов могла проанализировать, что пошло не так, и при необходимости принять корректирующие меры:
Одним из преимуществ этого решения для мониторинга является то, что оно показывает среднее время выполнения компонентов внутри кластера. Со временем решение может начать считать плохие средние значения нормой в среде ESXi с избыточной загрузкой. Тем не менее, оператор может оценить реальные значения и сравнить их с показателями других приложений, работающих на том же узле.
Это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Давайте посмотрим на новые возможности двух недавних релизов:
Релиз Lighthouse Point (0.99k) от 7 октября 2024
VMware Snapshot Inventory
Начиная с версии SexiGraf 0.99h, панель мониторинга «VI Offline Inventory» заменена на VMware Inventory с инвентаризацией ВМ, хостов и хранилищ данных (вскоре добавятся портгруппы и другие элементы). Эти новые панели имеют расширенные возможности фильтрации и значительно лучше подходят для крупных инфраструктур (например, с более чем 50 000 виртуальных машин). Это похоже на извлечение данных из RVtools, которое всегда отображается и актуально.
В релизе v0.99k появилось представление VM Snapshot Inventory:
Улучшения "Cluster health score" для VMware vSAN 8
Вместо того чтобы бесконечно нажимать на кнопку обновления на вкладке «Resyncing Components» в WebClient, начиная с версии SexiGraf 0.99b разработчики добавили панель мониторинга vSAN Resync:
Shell In A Box
В версии SexiGraf 0.99k разработчики добавили отдельный дэшборд Shell In A Box за обратным прокси-сервером, чтобы снова сделать отладку удобной.
Прочие улучшения:
Официальная поддержка vSphere и vSAN 8.3 API, а также Veeam Backup & Replication v12
Добавлен выбор версии в панель мониторинга VMware Evo Version
Добавлена многострочная панель в панель мониторинга репозиториев Veeam
Обработка учетных записей с очень ограниченными правами
Опция использования MAC-адреса вместо Client-ID при использовании DHCP
Добавлено имя хоста гостевой ОС в инвентаризацию виртуальных машин
Релиз St. Olga (0.99j) от 12 февраля 2024
В этой версии авторы добавили официальную поддержку новых API vSphere и vSAN 8.2, а также Veeam Backup & Replication v11+.
Новые возможности:
Поддержка Veeam Backup & Replication
Автоматическое слияние метрик ВМ и ESXi между кластерами (функция DstVmMigratedEvent в VROPS)
Количество путей до HBA
PowerShell Core 7.2.17 LTS
PowerCLI 13.2.1
Grafana 8.5.9 (не 8.5.27 из-за ошибки, появившейся в v8.5.10)
Ubuntu 20.04.6 LTS
Улучшения и исправления:
Метрика IOPS для виртуальных машин
Инвентаризация VMware VBR
История инвентаризации
Панель мониторинга эволюции версий активов VMware
Исправлено пустое значение datastoreVMObservedLatency на NFS
Различные исправления ошибок
SexiGraf теперь поставляется только в виде новой OVA-аппаратной версии, больше никаких патчей (за исключением крайних случаев). Для миграции необходимо использовать функцию Export/Import, чтобы извлечь данные из вашей предыдущей версии SexiGraf и перенести их в новую.
Актуальная версия SexiGraf доступна для бесплатной загрузки на странице Quickstart.
В обновлении платформы VMware Cloud Foundation 5.2 был представлен новый инструмент командной строки (CLI), называемый VCF Import Tool, который предназначен для преобразования или импорта существующих сред vSphere, которые в настоящее время не управляются менеджером SDDC, в частное облако VMware Cloud Foundation. Вы можете ознакомиться с демонстрацией работы инструмента импорта VCF в этом 6-минутном видео.
Инструмент импорта VCF позволяет клиентам ускорить переход на современное частное облако, предоставляя возможность быстро внедрить Cloud Foundation непосредственно в существующую инфраструктуру vSphere. Нет необходимости приобретать новое оборудование, проходить сложные этапы развертывания или вручную переносить рабочие нагрузки. Вы просто развертываете менеджер SDDC на существующем кластере vSphere и используете инструмент импорта для преобразования его в частное облако Cloud Foundation.
Импорт вашей существующей инфраструктуры vSphere в частное облако VCF происходит без сбоев, поскольку это прозрачно для работающих рабочих нагрузок. В общих чертах, процесс включает сканирование vCenter для обеспечения совместимости с VCF, а затем регистрацию сервера vCenter и его связанного инвентаря в менеджере SDDC. Зарегистрированные экземпляры сервера vCenter становятся доменами рабочих нагрузок VCF, которые можно централизованно управлять и обновлять через менеджер SDDC как часть частного облака VMware. После добавления в инвентарь Cloud Foundation все доступные операции менеджера SDDC становятся доступны для управления преобразованным или импортированным доменом. Это включает в себя расширение доменов путем добавления новых хостов и кластеров, а также применение обновлений программного обеспечения.
Обзор инструмента импорта VCF
Существует два способа начать работу с инструментом импорта VCF.
Если у вас еще нет развернутого виртуального модуля (Virtual Appliance) менеджера SDDC в вашем датацентре, первый шаг — вручную развернуть экземпляр устройства в существующей среде vSphere. Затем вы используете инструмент импорта VCF для преобразования этой среды в управляющий домен VMware Cloud Foundation.
Если в вашем датацентре уже работает экземпляр менеджера SDDC, просто обновите его до версии VCF 5.2 и используйте его для начала импорта существующих сред vSphere как доменов рабочих нагрузок VI. Обратите внимание, что помимо импорта и преобразования сред vSphere в VCF в качестве доменов рабочих нагрузок, инструмент импорта VCF также может быть использован для развертывания NSX в преобразованном или импортированном домене. Это можно сделать как во время преобразования/импорта, так и в качестве операции «Day-2», выполняемой в любое время после добавления среды в качестве домена рабочих нагрузок. Также в инструменте импорта есть функция синхронизации, которая позволяет управлять расхождением конфигураций между сервером vCenter и менеджером SDDC. Подробнее об этих функциях будет рассказано ниже.
Требования для использования инструмента импорта VCF
Чтобы начать работу с инструментом импорта VCF, необходимо выполнить несколько требований. Эти требования различаются в зависимости от того, преобразуете ли вы существующую среду vSphere в управляющий домен VCF или импортируете существующую среду vSphere как домен виртуальной инфраструктуры (VI). Начнем с рассмотрения требований, уникальных для преобразования управляющего домена VCF. Затем перейдем к требованиям, общим для обоих случаев использования — преобразования и импорта.
Примечание: требования и ограничения, указанные в этой статье, основаны на первоначальном релизе инструмента импорта VCF, доступного с VCF 5.2. Обязательно ознакомьтесь с Release Notes, чтобы узнать, применимы ли эти ограничения к версии VCF, которую вы используете.
Требования для преобразования кластера vSphere в управляющий домен VCF
Для преобразования существующей среды vSphere в управляющий домен VCF необходимо учитывать два основных требования.
Во-первых, среда vSphere, которую вы хотите преобразовать, должна работать на версии vSphere 8.0 Update 3 или выше. Это относится как к экземпляру сервера vCenter, так и к хостам ESXi. Эта версия vSphere соответствует спецификации (Bill of Materials, BOM) VCF 5.2. Это требование связано, в частности, с тем, что сначала нужно развернуть виртуальный модуль менеджера SDDC в кластере, а версия 5.2 этого устройства требует версий vCenter и ESXi 8.0 Update 3 (или выше).
Во-вторых, при преобразовании среды vSphere сервер vCenter должен работать в кластере, который будет преобразован. В документации это называется требованием «совместного размещения» сервера vCenter с кластером.
Требования для импорта кластера vSphere в домен VI VCF
Как и при преобразовании в новый управляющий домен, при импорте среды vSphere в домен VI VCF также необходимо учитывать два основных требования.
Во-первых, поддерживаемые версии vSphere для импорта в качестве домена VI — это vSphere 7.0 Update 3 и выше. Это включает как экземпляр сервера vCenter, так и хосты ESXi. Минимальная версия 7.0 с обновлением 3 соответствует версии vCenter и ESXi, которая входит в спецификацию VCF 4.5 (BOM).
Во-вторых, при импорте среды vSphere сервер vCenter должен работать либо в кластере, который преобразуется (совместно размещенный), либо в кластере в управляющем домене.
Общие требования при преобразовании и импорте кластеров vSphere
Помимо указанных выше требований, существуют следующие общие требования для преобразования и импорта инфраструктуры vSphere.
Все хосты внутри кластера vSphere должны быть однородными. Это означает, что все хосты в кластере должны быть одинаковыми по мощности, типу хранилища и конфигурации (pNIC, VDS и т.д.). Конфигурации серверов могут различаться между кластерами, но внутри одного кластера хосты должны быть одинаковыми.
Кластеры, которые будут преобразованы или импортированы, должны использовать один из трех поддерживаемых типов хранилищ: vSAN, NFS или VMFS на Fibre Channel (FC). Это часто вызывает путаницу, так как при развертывании с нуля (greenfield deployment) с использованием устройства Cloud Builder для управляющего домена требуется всегда использовать vSAN. Учтите, что требование vSAN не применяется к преобразованным управляющим доменам, где можно использовать vSAN, NFS или VMFS на FC.
При использовании vSAN минимальное количество хостов для управляющего домена всегда составляет четыре. Однако при использовании NFS или VMFS на FC минимальное количество хостов составляет три. Это также отличается от требований при развертывании с нуля с использованием Cloud Builder.
Режим расширенной связи (Enhanced Linked Mode, ELM) не поддерживается инструментом импорта VCF. Каждый экземпляр сервера vCenter, который будет преобразован или импортирован в качестве домена рабочих нагрузок VCF, должен находиться в собственной доменной структуре SSO. Таким образом, каждый преобразованный или импортированный экземпляр vCenter создаст изолированный домен рабочих нагрузок в VCF. Это может стать проблемой для клиентов, которые привыкли к централизованному управлению своей средой VCF через одну панель управления. Обратите внимание на новые дэшборды мониторинга VCF Operations (ранее Aria Operations), которые могут помочь смягчить это изменение.
Все кластеры в инвентаре vCenter должны быть настроены с использованием одного или нескольких выделенных vSphere Distributed Switches (VDS). Учтите, что стандартные коммутаторы vSphere (VSS) не поддерживаются. Более того, если в кластере настроен VSS, его необходимо удалить перед импортом кластера. Также важно отметить, что VDS не могут быть общими для нескольких кластеров vSphere.
В инвентаре vCenter не должно быть отдельных хостов ESXi. Отдельные хосты нужно либо переместить в кластер vSphere, либо удалить из инвентаря vCenter.
Во всех кластерах должно быть включено полное автоматическое распределение ресурсов (DRS Fully Automated), и на всех хостах должна быть настроена выделенная сеть для vMotion.
Все адаптеры vmkernel должны иметь статически назначенные IP-адреса. В рамках процесса преобразования/импорта в менеджере SDDC будет создан пул сетей с использованием этих IP-адресов. После завершения импорта эти IP-адреса не должны изменяться, поэтому они должны быть статически назначены.
Среды vSphere не могут иметь несколько адаптеров vmkernel, настроенных для одного и того же типа трафика.
Значимые ограничения инструмента импорта в VCF 5.2
После указания требований для использования инструмента импорта VCF важно отметить несколько ограничений, связанных с версией VCF 5.2, о которых нужно знать. Имейте в виду, что рабочие процессы импорта VCF включают функцию «проверки», которая сканирует инвентарь vCenter перед попыткой преобразования или импорта. Если обнаруживаются ограничения, процесс будет остановлен.
Следующие топологии не могут быть преобразованы или импортированы с использованием инструмента импорта VCF в версии 5.2:
Среда vSphere, настроенная с использованием NSX.
Среды vSphere, настроенные с балансировщиком нагрузки AVI.
Среды vSphere, настроенные с растянутыми кластерами vSAN Stretched Clusters.
Среды vSphere, где vSAN настроен только в режиме сжатия (compression-only mode).
Кластеры vSphere с общими распределенными коммутаторами vSphere (VDS).
Среды vSphere с включенной контрольной панелью IaaS (ранее vSphere with Tanzu).
Среды vSphere, настроенные с использованием протокола управления агрегированием каналов (LACP).
Среды VxRail.
Установка NSX на преобразованные и импортированные домены рабочих нагрузок
При обсуждении ограничений, связанных с инструментом импорта VCF, мы отметили, что нельзя преобразовывать или импортировать кластеры, настроенные для NSX. Однако после того, как домен будет преобразован/импортирован, вы можете использовать инструмент импорта VCF для установки NSX. Вы можете выбрать установку NSX одновременно с преобразованием/импортом или в любое время после этого в рамках операций Day-2.
Одна важная вещь, которую следует помнить при использовании инструмента импорта VCF для установки NSX на преобразованный или импортированный домен рабочих нагрузок, заключается в том, что виртуальные сети и логическая маршрутизация не настраиваются в процессе установки NSX. Инструмент импорта устанавливает NSX и настраивает распределенные группы портов в NSX Manager. Это позволяет начать использовать распределенный межсетевой экран NSX для защиты развернутых рабочих нагрузок. Однако для того, чтобы воспользоваться возможностями виртуальных сетей и логического переключения, предоставляемыми NSX, требуется дополнительная настройка, так как вам нужно вручную настроить туннельные эндпоинты хоста (TEPs).
Использование инструмента импорта VCF для синхронизации изменений с сервером vCenter
Помимо возможности импортировать существующую инфраструктуру vSphere в Cloud Foundation, инструмент импорта также предоставляет функцию синхронизации, которая позволяет обновлять менеджер SDDC с учетом изменений, внесенных в инвентарь сервера vCenter, что помогает поддерживать согласованность и точность всей среды.
При управлении инфраструктурой vSphere, которая является частью частного облака Cloud Foundation, могут возникнуть ситуации, когда вам потребуется внести изменения непосредственно в среду vSphere. В некоторых случаях изменения, сделанные непосредственно в инвентаре vCenter, могут не быть захвачены менеджером SDDC. Если инвентарь менеджера SDDC выйдет из синхронизации с инвентарем vCenter, это может временно заблокировать некоторые рабочие процессы автоматизации. Чтобы избежать этого, вы запускаете инструмент импорта CLI с параметром «sync», чтобы обновить инвентарь менеджера SDDC с учетом изменений, внесенных в конфигурацию vCenter.
Наверняка вы слышали о недавнем обновлении программного обеспечения CrowdStrike для Microsoft Windows, которое вызвало беспрецедентный глобальный сбой по всему миру (а может даже вы были непосредственно им затронуты). Несколько дней назад ИТ-администраторы работали круглосуточно, чтобы восстановить работоспособность тысяч, если не десятков тысяч систем Windows.
Текущий рекомендуемый процесс восстановления от CrowdStrike определенно болезненный, так как он требует от пользователей перехода в безопасный режим Windows для удаления проблемного файла. Большинство организаций используют Microsoft Bitlocker, что добавляет дополнительный шаг к уже и так болезненному ручному процессу восстановления, так как теперь необходимо найти ключи восстановления перед тем, как войти в систему и применить исправление.
Вильям Лам написал об этой ситуации. В течение нескольких часов после новостей от CrowdStrike он уже увидел ряд запросов от клиентов и сотрудников на предмет наличия автоматизированных решений или скриптов, которые могли бы помочь в их восстановлении, так как требование к любой организации вручную восстанавливать системы неприемлемо из-за масштабов развертываний в большинстве предприятий. Ознакомившись с шагами по восстановлению и размышляя о том, как платформа vSphere может помочь пользователям автоматизировать то, что обычно является ручной задачей, у него возникло несколько идей, которые могут быть полезны.
Скрипты, предоставленные в этой статье, являются примерами. Пожалуйста, тестируйте и адаптируйте их в соответствии с вашей собственной средой, так как они не были протестированы официально, и их поведение может варьироваться в зависимости от среды. Используйте их на свой страх и риск.
Платформа vSphere обладает одной полезной возможностью, которая до сих пор не всем известна, позволяющей пользователям автоматизировать отправку нажатий клавиш в виртуальную машину (VM), что не требует наличия VMware Tools или даже запущенной гостевой операционной системы.
Чтобы продемонстрировать, как может выглядеть автоматизированное решение для устранения проблемы CrowdStrike, Вильям создал прототип PowerCLI-скрипта под названием crowdstrike-example-prototype-remediation-script.ps1, который зависит от функции Set-VMKeystrokes. В настройке автора работает Windows Server 2019 с включенным Bitlocker, и он "смоделировал" директорию и конфигурационный файл CrowdStrike, которые должны быть удалены в рамках процесса восстановления. Вместо загрузки в безопасный режим, что немного сложнее, автор решил просто загрузиться в установщик Windows Server 2019 и перейти в режим восстановления, что позволило ему применить тот же процесс восстановления.
Ниже представлено видео, демонстрирующее автоматизацию и шаги, происходящие между PowerCLI-скриптом и тем, что происходит в консоли виртуальной машины. Вручную никакие действия не выполнялись:
В зависимости от вашей среды и масштаба, вам может потребоваться настроить различные значения задержек, и это следует делать в тестовой или разработческой среде перед развертыванием поэтапно.
В качестве альтернативы, автор также рекомендует и немного другой подход. Один из клиентов создал кастомный WindowsPE ISO, который содержал скрипт для удаления проблемного файла CrowdStrike, и всё, что им нужно было сделать, это смонтировать ISO, изменить порядок загрузки с жесткого диска на CDROM, после чего ISO автоматически выполнил бы процесс восстановления, вместо использования безопасного режима, что является довольно умным решением.
В любом случае, вот пример фрагмента PowerCLI-кода, который реконфигурирует виртуальную машину (поддерживается, когда ВМ выключена) для монтирования нужного ISO из хранилища vSphere и обновляет порядок загрузки так, чтобы машина автоматически загружалась с ISO, а не с жесткого диска.
$vmName = "CrowdStrike-VM"
$isoPath = "[nfs-datastore-synology] ISO/en_windows_server_version_1903_x64_dvd_58ddff4b.iso"
$primaryDisk = "Hard disk 1"
$vm = Get-VM $vmName
$vmDevices = $vm.ExtensionData.Config.Hardware.Device
$cdromDevice = $vmDevices | where {$_.getType().name -eq "VirtualCdrom"}
$bootDevice = $vmDevices | where {$_.getType().name -eq "VirtualDisk" -and $_.DeviceInfo.Label -eq $primaryDisk}
# Configure Boot Order to boot from ISO and then Hard Disk
$cdromBootDevice = New-Object VMware.Vim.VirtualMachineBootOptionsBootableCdromDevice
$diskBootDevice = New-Object VMware.Vim.VirtualMachineBootOptionsBootableDiskDevice
$diskBootDevice.DeviceKey = $bootDevice.key
$bootOptions = New-Object VMware.Vim.VirtualMachineBootOptions
$bootOptions.bootOrder = @($cdromBootDevice,$diskBootDevice)
# Mount ISO from vSphere Datastore
$cdromBacking = New-Object VMware.Vim.VirtualCdromIsoBackingInfo
$cdromBacking.FileName = $isoPath
$deviceChange = New-Object VMware.Vim.VirtualDeviceConfigSpec
$deviceChange.operation = "edit"
$deviceChange.device = $cdromDevice
$deviceChange.device.Backing = $cdromBacking
$deviceChange.device.Connectable.StartConnected = $true
$deviceChange.device.Connectable.Connected = $true
$spec = New-Object VMware.Vim.VirtualMachineConfigSpec
$spec.deviceChange = @($deviceChange)
$spec.bootOptions = $bootOptions
$task = $vm.ExtensionData.ReconfigVM_Task($spec)
$task1 = Get-Task -Id ("Task-$($task.value)")
$task1 | Wait-Task | Out-Null
Чтобы подтвердить, что изменения были успешно применены, вы можете использовать интерфейс vSphere или следующий фрагмент PowerCLI-кода:
Остается только запустить виртуальную машину, а затем, после завершения восстановления, можно отменить операцию, размонтировав ISO и удалив конфигурацию порядка загрузки, чтобы вернуть исходное поведение виртуальной машины.
В конце прошлого года компания VMware выпустила версию решения VMware Cloud Director 10.5.1, предназначенного для управления программно-определяемым датацентром сервис-провайдеров. Это был небольшой сервисный релиз продукта, а вот в vCD 10.6 появилось уже довольно много всего нового.
В этом последнем обновлении вы найдете значительные улучшения и новые функции в следующих областях:
Основная платформа
Трехуровневая аренда
VMware Cloud Director позволяет облачным провайдерам создавать многоуровневую организационную структуру через интерфейс пользователя, известную как модель трехуровневой аренды, для создания субпровайдерских организаций с ограниченными административными привилегиями над определенным набором арендаторов.
С этой возможностью облачные провайдеры могут предоставлять ограниченный доступ к конкретным ресурсам и услугам внутри своей инфраструктуры, при этом гарантируя, что каждый арендатор имеет контролируемый доступ только к нужным ресурсам. Эта усовершенствованная модель аренды также обеспечивает большую масштабируемость, гибкость и безопасность, так как облачные провайдеры могут легко управлять и выделять ресурсы на различных уровнях администрирования.
Этот инновационный подход позволяет облачным провайдерам принимать различные бизнес-модели, такие как:
Создание субпровайдерских организаций, что способствует вложенной многоуровневой аренде внутри крупных корпоративных организаций, позволяя создавать отдельные административные иерархии для разных отделов или дочерних компаний.
Перепродажа облачных услуг через партнеров или MSP (managed service providers).
Этот выпуск приносит возможность трехуровневой аренды во все аспекты ресурсов и услуг, доступных через VMware Cloud Director, делая его идеальным решением для облачных провайдеров, стремящихся предлагать гибкие и масштабируемые облачные услуги своим клиентам.
Увеличенные лимиты
Этот выпуск значительно увеличивает максимальные параметры в нескольких областях платформы, таких как:
Максимальное количество виртуальных машин на инстанс VMware Cloud Director увеличено до 55 000, независимо от состояния питания.
Количество одновременно поддерживаемых удаленных консолей увеличено до 22 000.
Максимальное количество пользователей, поддерживаемых платформой, увеличено до 300 000.
Организационная модель для группы виртуальных датацентров (Org VDC) была переработана в трехуровневую структуру. В рамках этого нового дизайна субпровайдер теперь может управлять группами датацентров, которые могут вмещать до 2000 участников (ранее 16) и делиться сетями и каналами связи между ними.
Множественные снапшоты ВМ и vApp
VMware Cloud Director теперь предлагает улучшенную гибкость для виртуальных машин и vApps с возможностью делать множественные снимки ВМ или vApp, до максимального количества, установленного вашим облачным провайдером.
Content Hub
Администраторы кластеров Kubernetes теперь могут определять точные контрольные точки доступа, предоставляя индивидуальным пользователям или группам персонализированные разрешения на доступ к конкретным кластерам, пространствам имен или приложениям. Эта функция позволяет создать multi-tenant архитектуру, позволяющую нескольким организациям безопасно сосуществовать в одном Kubernetes окружении, каждая с изолированным пространством имен для развертывания, управления и контроля своих контейнеризованных рабочих нагрузок.
Также была выпущена новая версия Content Hub Operator, которая работает нативно в кластере Kubernetes и использует протокол WebSocket для высокопроизводительной связи с VMware Cloud Director. Оператор также предоставляет отчеты о совместимости в реальном времени на портал арендатора, позволяя владельцам кластеров принимать информированные решения о времени обновления для обеспечения бесшовной интеграции с VMware Cloud Director.
Распределенный глобальный каталог
Он позволяет создать глобальную мультисайтовую облачную архитектуру, обеспечивая бесшовный доступ к каталогам через несколько сайтов VMware Cloud Director (VCD), предоставляя единый каталог для арендаторов, независимо от инстанса vCenter или инфраструктуры SDDC. Вы можете использовать независимые от поставщика решения для совместного хранения данных (такие как NetApp, Dell, vSAN и т.д.), чтобы реплицировать данные и обеспечить глобальную согласованность каталога.
Множественные протоколы IDP и локальные пользователи
VMware Cloud Director позволяет организациям использовать несколько протоколов поставщиков индентификации (IDP), включая LDAP, SAML и OpenId Connect (OIDC), для более комплексного подхода к аутентификации. Используя внешних поставщиков, вы можете воспользоваться последними достижениями в технологиях аутентификации. Стоит отметить, что локальные пользователи по-прежнему поддерживаются в текущем выпуске, их использование в производственной среде прекращается, но они будут полностью поддерживаться до следующего крупного выпуска VMware Cloud Director.
При развертывании шаблона ВМ на другом vCenter, используя VMware Cloud Director, система использует двухфазный подход для обеспечения эффективного развертывания. Изначально она пытается ускорить процесс путем клонирования шаблона ВМ напрямую, используя скорость и эффективность этого метода. Этот подход позволяет системе быстро создать новый инстанс ВМ без издержек на экспорт и импорт ВМ как OVF-файл. Однако, если операция клонирования сталкивается с любыми проблемами или ошибками, система автоматически переключается на более традиционный метод, используя экспорт/импорт OVF для развертывания ВМ. Этот резервный подход обеспечивает успешное завершение процесса развертывания, даже в случаях, когда клонирование может быть невозможным.
Улучшенное управление шифрованием
VMware Cloud Director 10.6 вводит несколько улучшений в функции управления шифрованием:
Одновременная регистрация нескольких поставщиков ключей, обеспечивающая большую гибкость и масштабируемость.
Имя кластера можно редактировать во время публикации поставщика ключей, что позволяет сервис-провайдерам легко идентифицировать, какой поставщик ключей принадлежит какому арендатору.
При аутентификации поставщика ключей или регистрации нового ключа пользователи теперь могут выбрать генерацию нового ключа для каждой операции шифрования, обеспечивая дополнительную безопасность.
Введена новая функция ротации ключей, позволяющая автоматическую ротацию ключей на основе настроек конфигурации. Этот процесс ненавязчив и обеспечивает бесшовное шифрование.
VMware Cloud Director 10.6 вводит новую функцию, позволяющую пользователям применять различные политики шифрования к различным политикам хранения, предоставляя большую гибкость и настройку в их стратегиях шифрования.
При удалении политики шифрования VMware Cloud Director 10.6 теперь предоставляет возможность "не перешифровывать" ранее зашифрованные данные.
Поддержка vSAN 4.1 NFS
VMware Cloud Director 10.6 теперь включает поддержку vSAN 4.1 NFS, обеспечивая безопасное совместное использование файлов с аутентификацией Kerberos. Эта интеграция позволяет использовать vSAN 4.1 как надежное и безопасное хранилище, предоставляя дополнительную возможность для совместного использования файлов в вашей организации.
Устранение уязвимости CVE-2024-22272
Для получения дополнительной информации об этой уязвимости и ее влиянии на продукты VMware, см. VMSA-2024-0014.
Сеть
Поддержка IPv6 для узлов VMware Cloud Director
VMware Cloud Director поддерживает развертывание ячеек устройств в IPv6 сетях, позволяя клиентам воспользоваться преимуществами современного сетевого протокола, сохраняя совместимость с существующей инфраструктурой.
Индивидуальный монитор здоровья
В рамках постоянных усилий по улучшению пользовательского опыта, VMware добавила Custom Health Monitors в дополнение к существующим HTTP-политикам. С этой функцией арендаторы теперь могут отслеживать и устранять неполадки различных характеристик здоровья своих балансируемых услуг, включая такие метрики, как время ответа, потеря пакетов и ошибки подключения. Это позволяет им принимать проактивные меры для поддержания надежности и отзывчивости услуг.
Логирование балансировщика нагрузки Avi
С новой функцией логирования Avi LB на уровне арендатора, арендаторы и облачные провайдеры теперь могут получить более глубокое понимание использования Avi LB. Эта функция предоставляет детализированное представление о действиях Avi LB, позволяя отслеживать модели использования, устранять события и экспортировать логи для аудита, соответствия и регуляторных целей.
WAF для Avi LB
Интеграция WAF (Web Application Firewall) с Avi LB и Cloud Director открывает новые возможности для клиентов по предоставлению дополнительных услуг своим конечным пользователям. Включение функций безопасности WAF в их портфель услуг позволяет обеспечить улучшенную защиту от веб-атак, повысить удовлетворенность клиентов и укрепить свои позиции на рынке.
С введением WAF появляются следующие преимущества:
Улучшенная безопасность: WAF помогает защищаться от веб-атак, таких как SQL-инъекции и межсайтовый скриптинг (XSS), фильтруя входящий трафик и блокируя вредоносные запросы.
Усиленное соответствие: WAF может помочь организациям соответствовать нормативным требованиям, предоставляя видимость веб-трафика и возможность блокировать определенные типы трафика или запросов.
Увеличение доверия клиентов: предлагая WAF как дополнительную услугу, организации могут продемонстрировать свою приверженность безопасности и укрепить доверие своих клиентов.
Конкурентное преимущество: WAF может стать ключевым отличием для организаций, стремящихся выделиться на переполненном рынке, так как обеспечивает дополнительный уровень безопасности и защиты.
Управление IP-адресами
Значительные обновления были внесены в управление IP-адресами, с упором на упрощение резервирования IP для рабочих нагрузок и выделения IP-адресов для долгоживущих услуг, таких как виртуальные IP-адреса балансировщиков нагрузки. Эти улучшения призваны соответствовать трехуровневой структуре разрешений, обеспечивая удобный опыт управления жизненным циклом IP-адресов, который исходит из IP-пулов для арендаторов, субпровайдеров и провайдеров.
IPsec VPN на шлюзах провайдеров и пограничных шлюзах
VMware Cloud Director расширил свои возможности IPsec VPN, включив установление туннеля на выделенных шлюзах провайдеров. Обновленная структура управления VPN теперь организована в трехуровневую модель, позволяя арендаторам, субпровайдерам и провайдерам настраивать и управлять VPN. С этой улучшенной возможностью провайдеры могут использовать Border Gateway Protocol (BGP) для контроля, какие IP-префиксы используют VPN. Более того, провайдеры и субпровайдеры могут автоматизировать настройку BGP для своих арендаторов, используя IP-пространства для управления сетевыми назначениями для публичного и частного адресации. Более того, провайдеры и субпровайдеры могут делегировать определенные конфигурации BGP своим арендаторам, предоставляя большую гибкость и контроль.
Новый UX для развертывания контроллеров Avi и NSX Cloud Connectors
VMware Cloud Director 10.6 вводит значительные улучшения в развертывание контроллеров Avi и NSX Cloud Connectors, тем самым увеличивая масштабируемость Avi LB. Новый пользовательский опыт позволяет администраторам легко добавлять больше облачных контроллеров к существующим контроллерам Avi, что увеличивает емкость и производительность. Кроме того, UX предоставляет ценные данные о потреблении ресурсов для контроллеров Avi, облаков NSX и пограничных шлюзов, что позволяет администраторам принимать информированные решения о выделении и оптимизации ресурсов.
Интеграция логов безопасности
VMware Cloud Director реализует прием и обработку логов, бесшовно подключаясь к VMware Aria Operations for Logs. Логи NSX Gateway Firewall и Distributed Firewall теперь автоматически обрабатываются VMware Aria Operations for Logs, предоставляя легкий доступ к этим логам через портал арендатора. Эта интеграция позволяет арендаторам быстро находить конкретные события, используя фильтры и временные диапазоны, и экспортировать логи в CSV-файлы для дальнейшего анализа и отчетности.
Object Storage Extension 3.1
В версии расширения VMware Cloud Director Object Storage Extension 3.1 появились следующие новые функции:
Поддержка MinIO для внешних кластеров Kubernetes.
Пересылка клиентских IP для настройки доступа к бакетам.
Улучшенный интерфейс резервного копирования и восстановления Kubernetes для лучшей видимости и управления.
Обновления OSIS (Object Storage Interoperability Service) для совместимых с S3 поставщиков хранилищ и асинхронного включения арендаторов.
Загрузите OSE 3.1 отсюда и прочитайте документацию по OSE 3.1 здесь.
Несколько полезных ресурсов о VMware Cloud Director 10.6
Начните с VMware Cloud Director 10.6, загрузив последнюю версию отсюда.
Для получения подробной информации о том, как использовать и настраивать VCD 10.6, ознакомьтесь с официальной документацией здесь.
Для получения дополнительных ресурсов и информации о VCD посетите специальную страницу VMware Cloud Director на сайте vmware.com здесь.
Для просмотра руководства по API прочитайте старое руководство по API здесь и руководство по OpenAPI здесь.
Вчера мы писали о новых возможностях последнего пакета обновлений VMware vSphere 8.0 Update 3, а сегодня расскажем что нового появилось в плане основных функций хранилищ (Core Storage).
Каждое обновление vSphere 8 добавляет множество возможностей для повышения масштабируемости, устойчивости и производительности. В vSphere 8 Update 3 продолжили улучшать и дорабатывать технологию vVols, добавляя новые функции.
Продолжая основной инженерный фокус на vVols и NVMe-oF, VMware также обеспечивает их поддержку в VMware Cloud Foundation. Некоторые функции включают дополнительную поддержку кластеризации MS WSFC на vVols и NVMe-oF, улучшения по возврату свободного пространства (Space Reclamation), а также оптимизации для VMFS и NFS.
Ключевые улучшения
Поддержка растянутых кластеров хранилищ (Stretched Clusters) для vVols
Новая спецификация vVols VASA 6
Кластеризация VMDK для NVMe/TCP
Ограничение максимального количества хостов, выполняющих Unmap
Поддержка NFS 4.1 Port Binding и nConnect
Дополнительная поддержка CNS/CSI для vSAN
vVols
Поддержка растянутого кластера хранилища vVols на SCSI
Растянутый кластер хранения vVols (vVols-SSC) был одной из самых запрашиваемых функций для vVols в течение многих лет, особенно в Европе. В vSphere 8 U3 добавлена поддержка растянутого хранилища vVols только на SCSI (FC или iSCSI). Первоначально Pure Storage, который был партнером по дизайну этой функции, будет поддерживать vVols-SSC, но многие из партнеров VMware по хранению также активно работают над добавлением данной поддержки.
Почему это заняло так много времени?
Одна из причин, почему реализация vVols-SSC заняла столько времени, заключается в дополнительных улучшениях, необходимых для защиты компонентов виртуальных машин (VMCP). Когда используется растянутое хранилище, необходимо наличие процесса для обработки событий хранения, таких как Permanent Device Loss (PDL) или All Paths Down (APD). VMCP — это функция высокой доступности (HA) vSphere, которая обнаруживает сбои хранения виртуальных машин и обеспечивает автоматическое восстановление затронутых виртуальных машин.
Сценарии отказа и восстановления
Контейнер/datastore vVols становится недоступным. Контейнер/datastore vVols становится недоступным, если либо все пути данных (к PE), либо все пути управления (доступ к VP, предоставляющим этот контейнер) становятся недоступными, либо если все пути VASA Provider, сообщающие о растянутом контейнере, отмечают его как UNAVAILABLE (новое состояние, которое VP может сообщить для растянутых контейнеров).
PE контейнера vVols может стать недоступным. Если PE для контейнера переходит в состояние PDL, то контейнер также переходит в состояние PDL. В этот момент VMCP будет отвечать за остановку виртуальных машин на затронутых хостах и их перезапуск на других хостах, где контейнер доступен.
Контейнер или PE vVols становится доступным снова или восстанавливается подключение к VP. Контейнер вернется в доступное состояние из состояния APD, как только хотя бы один VP и один PE станут доступны снова. Контейнер вернется в доступное состояние из состояния PDL только после того, как все виртуальные машины, использующие контейнеры, будут выключены, и все клиенты, имеющие открытые файловые дескрипторы к хранилищу данных vVols, закроют их.
Поведение растянутого контейнера/хранилища данных довольно похоже на VMFS, и выход из состояния PDL требует уничтожения PE, что может произойти только после освобождения всех vVols, связанных с PE. Точно так же, как VMFS (или устройство PSA) не может выйти из состояния PDL, пока все клиенты тома VMFS (или устройства PSA) не закроют свои дескрипторы.
Требования
Хранилище SCSI (FC или iSCSI)
Макс. время отклика между хостами vSphere — 11 мс
Макс. время отклика массива хранения — 11 мс
Выделенная пропускная способность сети vSphere vMotion — 250 Мбит/с
Один vCenter (vCenter HA не поддерживается с vVols)
Контроль ввода-вывода хранения не поддерживается на datastore с включенным vVol-SSC
Дополнительная поддержка UNMAP
Начиная с vSphere 8.0 U1, config-vvol теперь создается с 255 ГБ VMFS vVol вместо 4 ГБ. Это добавило необходимость в возврате свободного пространства в config-vvol. В 8.0 U3 VMware добавила поддержку как ручного (CLI), так и автоматического UNMAP для config-vvol для SCSI и NVMe.
Это гарантирует, что при записи и удалении данных в config-vvol обеспечивается оптимизация пространства для новых записей. Начиная с vSphere 8.0 U3, также поддерживается команда Unmap для хранилищ данных NVMe-oF, а поддержка UNMAP для томов SCSI была добавлена в предыдущем релизе.
Возврат пространства в хранилищах виртуальных томов vSphere описан тут.
Кликните на картинку, чтобы посмотреть анимацию:
Поддержка кластеризации приложений на NVMe-oF vVols
В vSphere 8.0 U3 VMware расширила поддержку общих дисков MS WSFC до NVMe/TCP и NVMe/FC на основе vVols. Также добавили поддержку виртуального NVMe (vNVME) контроллера для гостевых кластерных решений, таких как MS WSFC.
Эти функции были ограничены SCSI на vVols для MS WSFC, но Oracle RAC multi-writer поддерживал как SCSI, так и NVMe-oF. В vSphere 8.0 U3 расширили поддержку общих дисков MS WSFC до vVols на базе NVMe/TCP и NVMe/FC. Также была добавлена поддержка виртуального NVMe (vNVME) контроллера виртуальной машины в качестве фронтенда для кластерных решений, таких как MS WSFC. Обратите внимание, что контроллер vNVMe в качестве фронтенда для MS WSFC в настоящее время поддерживается только с NVMe в качестве бэкенда.
Обновление отчетности по аутентификации хостов для VASA Provider
Иногда при настройке Storage Provider для vVols некоторые хосты могут не пройти аутентификацию, и это может быть сложно диагностировать. В версии 8.0 U3 VMware добавила возможность для vCenter уведомлять пользователей о сбоях аутентификации конкретных хостов с VASA провайдером и предоставили механизм для повторной аутентификации хостов в интерфейсе vCenter. Это упрощает обнаружение и решение проблем аутентификации Storage Provider.
Гранулярность хостов Storage Provider для vVols
С выходом vSphere 8 U3 была добавлена дополнительная информация о хостах для Storage Provider vVols и сертификатах. Это предоставляет клиентам и службе поддержки дополнительные детали о vVols при устранении неполадок.
NVMe-oF
Поддержка NVMe резервирования для кластерного VMDK с NVMe/TCP
В vSphere 8.0 U3 была расширена поддержка гостевой кластеризации до NVMe/TCP (первоначально поддерживалась только NVMe/FC). Это предоставляет клиентам больше возможностей при использовании NVMe-oF и желании перенести приложения для гостевой кластеризации, такие как MS WSFC и Oracle RAC, на хранилища данных NVMe-oF.
Поддержка NVMe Cross Namespace Copy
В предыдущих версиях функция VAAI, аппаратно ускоренное копирование (XCOPY), поддерживалась для SCSI, но не для NVMe-oF. Это означало, что копирование между пространствами имен NVMe использовало ресурсы хоста для передачи данных. С выпуском vSphere 8.0 U3 теперь доступна функция Cross Namespace Copy для NVMe-oF для поддерживаемых массивов. Применение здесь такое же, как и для SCSI XCOPY между логическими единицами/пространствами имен. Передачи данных, такие как копирование/клонирование дисков или виртуальных машин, теперь могут работать значительно быстрее. Эта возможность переносит функции передачи данных на массив, что, в свою очередь, снижает нагрузку на хост.
Кликните на картинку, чтобы посмотреть анимацию:
VMFS
Сокращение времени на расширение EZT дисков на VMFS
В vSphere 8.0 U3 был реализован новый API для VMFS, чтобы ускорить расширение блоков на диске VMFS, пока диск используется. Этот API может работать до 10 раз быстрее, чем существующие методы, при использовании горячего расширения диска EZT на VMFS.
Виртуальные диски на VMFS имеют тип аллокации, который определяет, как резервируется основное хранилище: Thin (тонкое), Lazy Zeroed Thick (толстое с занулением по мере обращения) или Eager Zeroed Thick (толстое с предварительным занулением). EZT обычно выбирается на VMFS для повышения производительности во время выполнения, поскольку все блоки полностью выделяются и зануляются при создании диска. Если пользователь ранее выбрал тонкое выделение диска и хотел преобразовать его в EZT, этот процесс был медленным. Новый API позволяет значительно это ускорить.
Кликните на картинку для просмотра анимации:
Ограничение количества хостов vSphere, отправляющих UNMAP на VMFS datastore
В vSphere 8.0 U2 VMware добавила возможность ограничить скорость UNMAP до 10 МБ/с с 25 МБ/с. Это предназначено для клиентов с высоким уровнем изменений или массовыми отключениями питания, чтобы помочь уменьшить влияние возврата пространства на массив.
Кликните на картинку для просмотра анимации:
По умолчанию все хосты в кластере, до 128 хостов, могут отправлять UNMAP. В версии 8.0 U3 добавлен новый параметр для расширенного возврата пространства, называемый Reclaim Max Hosts. Этот параметр может быть установлен в значение от 1 до 128 и является настройкой для каждого хранилища данных. Чтобы изменить эту настройку, используйте ESXCLI. Алгоритм работает таким образом, что после установки нового значения количество хостов, отправляющих UNMAP одновременно, ограничивается этим числом. Например, если установить максимальное значение 10, в кластере из 50 хостов только 10 будут отправлять UNMAP на хранилище данных одновременно. Если другие хосты нуждаются в возврате пространства, то, как только один из 10 завершит операцию, слот освободится для следующего хоста.
Пример использования : esxcli storage vmfs reclaim config set -l <Datastore> -n <number_of_hosts>
Вот пример изменения максимального числа хостов, отправляющих UNMAP одновременно:
PSA
Поддержка уведомлений о производительности Fabric (FPIN, ошибки связи, перегрузка)
VMware добавила поддержку Fabric Performance Impact Notification (FPIN) в vSphere 8.0 U3. С помощью FPIN слой инфраструктуры vSphere теперь может обрабатывать уведомления от SAN-коммутаторов или целевых хранилищ о падении производительности каналов SAN, чтобы использовать исправные пути к устройствам хранения. Он может уведомлять хосты о перегрузке каналов и ошибках. FPIN — это отраслевой стандарт, который предоставляет средства для уведомления устройств о проблемах с соединением.
Вы можете использовать команду esxcli storage FPIN info set -e= <true/false>, чтобы активировать или деактивировать уведомления FPIN.
Кликните на картинку, чтобы посмотреть анимацию:
NFS
Привязка порта NFS v4.1 к vmk
Эта функция добавляет возможность байндинга соединения NFS v4.1 к определенному vmknic для обеспечения изоляции пути. При использовании многопутевой конфигурации можно задать несколько vmknic. Это обеспечивает изоляцию пути и помогает повысить безопасность, направляя трафик NFS через указанную подсеть/VLAN и гарантируя, что трафик NFS не использует сеть управления или другие vmknic. Поддержка NFS v3 была добавлена еще в vSphere 8.0 U1. В настоящее время эта функция поддерживается только с использованием интерфейса esxcli и может использоваться совместно с nConnect.
Начиная с версии 8.0 U3, добавлена поддержка nConnect для хранилищ данных NFS v4.1. nConnect предоставляет несколько соединений, используя один IP-адрес в сессии, таким образом расширяя функциональность агрегации сессий для этого IP. С этой функцией многопутевая конфигурация и nConnect могут сосуществовать. Клиенты могут настроить хранилища данных с несколькими IP-адресами для одного сервера, а также с несколькими соединениями с одним IP-адресом. В настоящее время максимальное количество соединений ограничено 8, значение по умолчанию — 1. Текущие версии реализаций vSphere NFSv4.1 создают одно соединение TCP/IP от каждого хоста к каждому хранилищу данных. Возможность добавления нескольких соединений на IP может значительно увеличить производительность.
При добавлении нового хранилища данных NFSv4.1, количество соединений можно указать во время монтирования, используя команду:
Общее количество соединений, используемых для всех смонтированных хранилищ данных NFSv4.1, ограничено 256.
Для существующего хранилища данных NFSv4.1, количество соединений можно увеличить или уменьшить во время выполнения, используя следующую команду:
esxcli storage nfs41 param set -v <volume-label> -c <number_of_connections>
Это не влияет на многопутевую конфигурацию. NFSv4.1 nConnect и многопутевые соединения могут сосуществовать. Количество соединений создается для каждого из многопутевых IP.
В настоящее время CNS поддерживает только 100 файловых томов. В vSphere 8.0 U3 этот лимит увеличен до 250 томов. Это поможет масштабированию для клиентов, которым требуется больше файловых хранилищ для постоянных томов (PVs) или постоянных запросов томов (PVCs) в Kubernetes (K8s).
Поддержка файловых томов в топологии HCI Mesh в одном vCenter
Добавлена поддержка файловых томов в топологии HCI Mesh в пределах одного vCenter.
Поддержка CNS на TKGs на растянутом кластере vSAN
Появилась поддержка растянутого кластера vSAN для TKGs для обеспечения высокой доступности.
Миграция PV между несвязанными datastore в одном VC
Возможность перемещать постоянный том (PV), как присоединённый, так и отсоединённый, с одного vSAN на другой vSAN, где нет общего хоста. Примером этого может быть перемещение рабочей нагрузки Kubernetes (K8s) из кластера vSAN OSA в кластер vSAN ESA.
Поддержка CNS на vSAN Max
Появилась поддержка развертывания CSI томов для vSAN Max при использовании vSphere Container Storage Plug-in.
Для других типов экземпляров VMware Cloud на AWS включено хранилище vSAN, которое базируется на локальных дисках каждого хоста. Хранилища данных vSAN растут вместе с кластером по мере добавления новых узлов. С m7i количество хранилища не зависит от числа хостов, и вы можете настроить его в зависимости от требований к хранилищу.
Ниже рассмотрим производительность виртуальных машин SQL Server, работающих на 3-узловом кластере m7i с хранилищем NFS, по сравнению с 3-узловым кластером i4i с хранилищем vSAN. Инстансы m7i основаны на процессорах Intel, которые на одно поколение новее, чем i4i. Вот чем отличаются эти инстансы:
Методология
Для тестов использовался набор ВМ с 16 vCPU и 24 vCPU. Поскольку экземпляры m7i имели 48 ядер, как 16 vCPU, так и 24 vCPU были равномерно распределены по общему количеству ядер, что облегчало сравнение производительности и делало его понятным. Для поддержки максимального числа ВМ с 16 vCPU на кластере m7i каждой ВМ назначили 60 ГБ ОЗУ.
Для тестов использовали ВМ Windows Server 2022 с установленным Microsoft SQL Server 2022 и применили открытый инструментарий бенчмаркинга DVD Store 3.5 для запуска нагрузок OLTP-приложений на SQL Server и измерения результатов. DVD Store симулирует онлайн-магазин, где клиенты просматривают, оставляют отзывы и оценивают, регистрируются и покупают продукты. Результаты выражаются в заказах в минуту (OPM), что является мерой пропускной способности. Чем выше показатели OPM - тем лучше.
Результаты производительности ВМ SQL Server с 24 vCPU против 16 vCPU
Результаты на рисунках 1 и 2 показывают производительность ВМ с 24 vCPU и 16 vCPU. Линия обозначает общую пропускную способность в OPM по всем ВМ в каждом тесте. Количество ВМ увеличивается в каждом тесте, начиная с 1 и заканчивая максимально возможным, исходя из количества vCPU, соответствующих числу доступных потоков в кластере.
Темп прироста OPM замедляется, когда количество vCPU превышает количество физических ядер и необходимо использовать второй логический поток (hyperthread) на каждом ядре. Это начинается с 8 и 12 ВМ для тестов с 24 и 16 vCPU соответственно.
Столбцы в каждом графике представляют использование CPU трех хостов для каждого теста. По мере добавления ВМ, VMware Distributed Resource Scheduler (DRS) автоматически размещал и, возможно, динамически перемещал ВМ между хостами для управления нагрузкой. Как показывают результаты, это поддерживало использование CPU на всех хостах довольно стабильным, даже когда нагрузка увеличивалась.
Последняя точка данных в тесте с 16 vCPU (рисунок 2) показывает небольшое снижение OPM, поскольку на этом этапе теста кластер немного перегружен. Несмотря на это, можно было продолжить масштабирование производительности кластера m7i, добавляя больше инстансов. В этих тестах был использован только кластер из 3 инстансов, но можно было бы добавить больше инстансов в кластер для увеличения его емкости.
Рисунок 1 - производительность виртуализированного SQL Server и использование CPU ESXi для кластера из 3 хостов VMware Cloud на AWS с 24 vCPU на ВМ:
Рисунок 2 - производительность виртуализированного SQL Server и использование CPU ESXi для кластера из 3 хостов VMware Cloud на AWS с 16 vCPU на ВМ:
Рисунок 3 сравнивает производительность ВМ с 16 vCPU и 24 vCPU таким образом, что в каждом тестовом случае назначалось одинаковое общее количество vCPU. Например, для 48 vCPU 2?24 vCPU сравниваются с 3?16 vCPU (по сумме - 48 в обоих случаях).
Рисунок 3 - производительность ВМ SQL Server: 16 vCPU по сравнению с 24 vCPU:
Сравнение производительности m7i с i4i
Те же ВМ были перенесены на кластер i4i и тесты повторили. Важно отметить, что чтобы сохранить ВМ максимально идентичными, им не увеличивали объем RAM, несмотря на то, что в кластере i4i было примерно в 2,5 раза больше RAM.
Как показывает рисунок 4, результаты для i4i были схожи в плане OPM и использования CPU хоста. Основное отличие: получилось запустить до 24 ВМ на i4i против максимума 18 ВМ на m7i. Это связано с большим количеством ядер и большей памятью в экземплярах i4i.
Рисунок 4 - трехузловой кластер i4i VMware Cloud on AWS: SQL Server ВМ и использование CPU хоста на ВМ с 16 vCPU по сравнению с vSAN:
Рисунок 5 показывает различия между m7i и i4i. Поскольку отдельные ядра экземпляров m7i имеют более высокую производительность, чем ядра кластера i4i, рисунок 5 показывает преимущество в производительности на левой стороне графика. Как только экземплярам m7i необходимо полагаться на второй логический поток (hyperthread) от каждого физического ядра для поддержки рабочих нагрузок, производительность i4i становится схожей. И, наконец, когда экземпляры i4i полностью используют преимущество большего количества ядер, их производительность превышает производительность m7i.
Рисунок 5 - различие между m7i и i4i:
Тестирование производительности говорит о хорошей работе SQL Server на m7i в рамках предоставляемой экземплярами m7i ресурсной емкости. Поскольку экземпляры m7i имеют меньше ядер и меньше памяти, чем i4i, важно использовать инструмент VMC Sizer, чтобы убедиться, что платформа соответствует потребностям баз данных.
Также наблюдались немного более высокие задержки с подключенным к m7i хранилищем NFS, но в целом это не оказало большого влияния на результаты тестов. Важно также правильно подобрать хранилище NFS, подключенное к m7i, и установить для хранилища IOPs и пропускную способность на уровни, соответствующие требованиям рабочей нагрузки.
VMware Cloud Foundation (VCF) — это решение для частного облака от Broadcom, основанное на виртуализации вычислений, сетевых функций и хранилищ, предоставляющее клиентам возможность реализации модели облачной операционной системы на онпремизных площадках клиентов (более подробно об этом тут, тут и тут). Оно предлагает такие преимущества, как простота развертывания и управление жизненным циклом с использованием предварительно проверенного списка ПО (Bill of Materials, BOM), который тщательно тестируется на совместимость.
Хранение данных (критически важная часть частного облака) поддерживается в двух категориях: Основное (Principal) и Дополнительное (Supplemental).
Основное хранилище (Principal Storage)
Основное хранилище настраивается при создании нового домена рабочей нагрузки (Workload Domain) или кластера в консоли SDDC Manager. После создания тип основного хранилища для кластера изменить нельзя. Однако Workload Domain может включать несколько кластеров с собственными типами основного хранилища.
Основные варианты хранения данных (principal storage) включают:
vSAN
vVols
NFSv3
VMFS на FC-хранилищах
Следует отметить, что vSAN является единственно поддерживаемым типом основного хранилища для всех кластеров в управляющем домене (Management Domain). vSAN требуется для управляющего домена, поскольку он предсказуем с точки зрения производительности. vSAN предоставляет высокопроизводительное решение для хранения данных Enterprise-уровня для SDDC. Использование vSAN исключает внешние зависимости и облегчает использование средств автоматизации для инициализации управляющего домена VCF. Во время первоначальной установки VCF Cloud Builder инициализирует все основные компоненты центра обработки данных, определяемые программно - такие как vSphere, NSX и vSAN, на минимально необходимом количестве хостов. Этот процесс первоначального запуска в среднем занимает около двух часов.
Дополнительное хранилище (Supplemental storage)
Supplemental storage предоставляет дополнительную емкость кластеру и рекомендуется для данных Tier-2 или Tier-3, таких как библиотеки контента vSphere, шаблоны виртуальных машин, резервные копии, образы ISO и т. д. Дополнительное хранилище требует ручной настройки, не интегрировано и не отображается в SDDC Manager.
Начиная с версии 5.1, vSAN поддерживает как OSA (оригинальная архитектура хранения), так и ESA (экспресс архитектура хранения). vSAN ESA оптимизирован для использования с высокопроизводительными устройствами хранения нового поколения на базе NVMe, чтобы обеспечить еще более высокие уровни производительности для требовательных рабочих нагрузок, таких как OLTP и генеративный AI. Broadcom рекомендует использовать vSAN ESA в качестве основного хранилища для всех доменов рабочих нагрузок, чтобы получить все преимущества управления и обслуживания полностью программно-определенного стека.
vSAN также обновляется и патчится через LCM (Lifecycle Manager) в SDDC Manager. Обновление и патчинг хранилищ, отличных от vSAN, является ручной задачей и не входит в процедуры управления жизненным циклом, реализованные в SDDC Manager. Для обеспечения поддержки, само хранилище и его HBA необходимо проверять на соответствие VMware Compatibility Guide, когда vSAN не используется.
vSAN использует движок Storage Policy-Based Management (SPBM), который позволяет управлять политиками хранения на уровне виртуальных машин, а не на уровне всего хранилища (datastore). С помощью этого механизма вы можете управлять всеми хранилищами инфраструктуры VCF. Если у вас большая инфраструктура, то необходимо использовать программные средства автоматизации, так как вручную управлять LUN и виртуальными томами и их возможностями очень проблематично в большом масштабе.
vSAN является рекомендуемым решением для хранения данных рабочих нагрузок по вышеупомянутым причинам. Однако VMware понимает, что среды разных клиентов не идентичны, и единый для всех подход не работает. Именно поэтому VCF поддерживает разнообразие типов основного и дополнительного хранилища. Эта гибкость с другими вариантами хранения предоставляет клиентам свободу выбора и позволяет VCF удовлетворить разнообразные потребности производственных сред клиентов.
Важно понимать широкий спектр требований, таких как производительность, доступность, емкость, ожидаемый рост и инвестиции в существующую инфраструктуру. В этой связи для получения дополнительной информации о VMware Cloud Foundation и требованиях к хранилищу, пожалуйста, обратитесь к следующим ресурсам:
В продукт VMware Skyline Advisor Pro, предназначенный для генерации умных проактивных рекомендаций (Findings), новые фичи добавляются каждый месяц (правда, в последний раз мы писали несколько месяцев назад об этом тут). Результаты приоритезируются на основе актуальных проблем при обращениях в техническую поддержку VMware, особенностей, выявленных в процессе обзора работы с тикетами, уязвимостей безопасности, проблем, выявленных инжиниринговой командой VMware, а также улучшений предлагаемых клиентами.
В январе было выпущено 60 новых рекомендаций. Из них 37 основаны на текущих проблемах, 9 - на обзорах после работы с тикетами, 1 - на основе рекомендаций безопасности VMSA и 12 - на основе предложений пользователей. В VMware выбрали несколько из этих результатов, которые наиболее ценны в этом релизе - приведем их ниже.
Уязвимости безопасности
В критическом патче VMSA-2024-0001 обновления VMware Aria Automation (ранее известного как vRealize Automation) решают проблему отсутствия контроля доступа (CVE-2023-34063). Аутентифицированный злоумышленник может использовать уязвимость так, что это приведет к несанкционированному доступу к удаленным организациям и рабочим процессам. Эта проблема была устранена в Aria Automation 8.16. Также доступны постпатчи для Aria Automation 8.11.2, 8.12.2, 8.13.1 и 8.14.1, которые будут добавлены в VMware Skyline Advisor Pro в будущем.
Обзор после эскалации тикетов
Техническая поддержка VMware разработала процесс ревью после эскалации. Инженеры анализируют критические тикеты, поступающие команде управления эскалациями, для которых определяются шаги для предотвращения таких эскалаций в будущем с другими клиентами. Одним из результатов этого является создание рекомендаций Skyline. Техническая поддержка VMware разработала строгий процесс обзора после эскалации для анализа критических ситуаций. Основная цель - всесторонний анализ этих эскалаций, выявление корневых причин и формулировка мер предотвращения.
В KB 95965 для vSphere 8.0 Update 2 файлы Changed Block Tracking (CBT) могут стать несогласованными, что может привести к неправильной записи резервных копий. Эта проблема проявляется только при создании резервных копий после расширения диска ВМ в горячем режиме. Простое изменение размера диска выключенной машины не вызовет этой проблемы. Ситуация может возникнуть с дисками всех типов хранилищ (VVOL, VMFS, NFS, vSAN). Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление о выходе исправления.
Также в KB 96065 для vCenter Server 8.0 Update 2 при попытке выполнения операций с виртуальными машинами операция висит и завершается после долгого времени или не завершается вовсе. Из-за нечувствительности к регистру символов в полном имени хоста vCenter Server в URL-адресе назначения умных прокси (Envoy sidecar proxy), при использовании верхнего регистра символов в именах хостов vCenter Server получаются висячие вызовы к службе VSM. Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление о выходе исправления.
Ну и в KB 96049 для vCenter Server 8.0U2 описана проблема, проявляющася при попытке выполнения операций с виртуальными машинами - операция висит и завершается, либо не завершается вовсе. Корневой причиной является отсутствие файлов jar в пакете службы VSM. Инженеры знают о данной проблеме и активно работают над ее решением. Подпишитесь на статью в базе знаний, чтобы получить уведомление, когда будет доступно исправление.
Ну а полный список новых рекомендаций для релиза Skyline Advisor Pro Proactive Findings – January 2024 Edition вы можете посмотреть тут.
Компания VMware выпустила очень интересную лабораторную работу для самостоятельного изучения расширенных тем, касающихся решения для создания отказоустойчивых кластеров VMware vSAN. В рамках практических заданий лабы VMware vSAN - Advanced Topics (HOL-2409-32-HCI) вы узнаете, как настроить vSAN для предоставления файловых сервисов, как vSAN может делить свою емкость с другими кластерами, и исследуете повышенную доступность, которую предлагает растянутый кластер.
Основные темы:
Услуги по работе с файлами (30 минут) - настройте vSAN для активации общих ресурсов NFS/SMB для предоставления услуг по работе с файлами конечным пользователям и приложениям.
Модель гиперконвергентной инфраструктуры HCI (также 30 минут) - позвольте vSAN делить свою емкость с другими кластерами vSphere/vSAN.
Архитектура растянутого кластера vSAN Stretched Cluster (время определяется самостоятельно) - повысьте доступность за счет распределения кластера vSAN между географически разнесенными порщадками.
Эта лаба отлично подходит для ИТ-специалистов и администраторов, желающих углубить свои знания о продукте vSAN и его применении в сложных распределенных средах.
Основная ссылка для начала работы - HOL-2409-32-HCI. Если вы только начинаете знакомство с VMware vSAN, то вам подойдет лабораторная работа VMware vSAN - Getting Started (HOL-2409-31-HCI).
Большинство администраторов уже знакомы с новой функциональностью, которая доступна в новой версии платформы виртуализации VMware vSphere 8 Update 2, о которой было объявлено в рамках конференции VMware Explore 2023. Сегодня мы поговорим об улучшених подсистемы работы с хранилищами (Core Storage).
vSphere 8 U2 содержит ряд важных нововведений, и область хранения данных не является исключением. Как вы, вероятно, заметили, VMware в последнее время делает акцент на технологиях vSAN, vVols и NVMeoF, и в этом году особое внимание уделяется vVols. В vSphere 8 было много важных усовершенствований. Например, новые спецификации VASA для vVols, улучшенная производительность и надежность, расширенное управление сертификатами и поддержка NVMeoF - и это лишь некоторые из них.
Хотя в vSphere 8 Update 2 и нет большого количества новых функций хранения, тем не менее, имеются некоторые важные обновления. vVols, NVMeoF, VMFS и NFS получили улучшения и функции, которые оценят многие администраторы.
Улучшения vVols
Расширение Online Shared Disks для vVols
В релизе vSphere 6.7 была добавлена поддержка постоянных резерваций SCSI3-Persistent Reservations для vVols. Эта функция позволяет приложениям для кластеризации контролировать блокировку общих дисков. Примером приложения, требующего SCSI3-PR для общих дисков в кластере, является Microsoft WSFC.
Однако одной из последних функций, которые были у RDM, но не у vVols, была возможность расширять общий диск в онлайн-режиме в некоторых приложениях, таких как Microsoft WSFC. Теперь же и vVols поддерживает горячее расширение общих дисков с использованием постоянных резерваций SCSI3. Это позволяет расширять общие диски без необходимости выключать кластер приложений. Теперь у RDM нет преимуществ перед vVols. Администраторы могут мигрировать свои приложения MS WSFC на vVols и избавиться от RDM. Это значительно упрощает управление виртуальным хранилищем, снижает сложность и при этом сохраняет функции, основанные на массивах.
Кликните на картинку для просмотра анимации этого процесса:
Поддержка онлайн-расширения диска vVols с Oracle RAC
В этом релизе, помимо MS WSFC, была добавлена поддержка горячего расширения и для дисков Oracle RAC с использованием режима Multi-Writer. Для расширения кластерных дисков теперь не требуется простоя. Это можно выполнять как на дисках SCSI, так и NVMe vVols. Это также позволяет клиентам мигрировать с томов RDM.
In-band миграция томов vVols
Теперь доступна поддержка миграции пространств имен NVMe vVol внутри групп ANA. Эта функциональность обеспечивает эквивалентность примитиву перепривязки SCSI и позволяет администратору хранилища балансировать нагрузку ввода-вывода по объектам Protocol Endpoint (PE).
Автоматическое восстановление из состояния PDL для PE vVol
Ранее, когда PE переходил в состояние PDL и затем возвращался, стек PSA должен был перезапустить устройство (уничтожить и снова обнаружить пути). Это могло произойти только после закрытия объектов vVol, использующих PE. В этом релизе, ВМ будут автоматически завершены в случаях, когда мы обнаруживаем, что PE, к которому привязаны vVols ВМ, находится в PDL. Это дополнительно повышает устойчивость и восстановление при определенных типах сбоев подсистемы хранения.
Поддержка 3rd party MPP для NVMe vVols
Позволяет MPP (политике многопутевого доступа) от сторонних разработчиков поддерживать NVMe vVols. Это дает возможность партнерам VMware использовать свою клиентскую политику MPP.
Поддержка UNMAP для конфигурационного vVol
Начиная с vSphere 8.0 U1, конфигурационные vVols теперь создаются как тонкие диски с максимальным размером 255 ГБ и форматируются с использованием VMFS-6. В этом релизе есть поддержка esxcli для выполнения процедуры unmap для конфигурационных vVols.
Улучшения NVMeoF
Поддержка типа контроллера vNVMe для MS WSFC
В vSphere 7 был добавлен новый контроллер виртуальных машин - vNVMe, но изначально он не поддерживался для использования с WSFC. В vSphere 8 была добавлена поддержка кластеризованных приложений на хранилищах данных NVMeoF. В vSphere 8 U2 техническая команда VMware сертифицировала контроллер vNVMe для использования с Microsoft WSFC. Теперь вы можете использовать NVMe с полной поддержкой для приложений WSFC. Изначально это поддерживается только с SCSI vVols.
Поддержка кластеризации Oracle RAC с vVols NVMe (FC, TCP)
Была добавлена поддержка кластеризованных дисков Oracle RAC vVol, размещаемых на бэкенде NVMe. Это включает NVMe-FC vVols и NVMe-TCP vVols.
Включение поддержки vNVMe с Oracle RAC (vVols)
Была добавлена поддержка использования контроллера vNVMe в качестве фронтенда для кластеризации в режиме multi-writer (Oracle RAC).
Улучшения VMFS
Улучшена производительность офлайн-консолидации снапшотов SE Sparse.
Производительность офлайн-консолидации снапшотов SE Sparse в этом релизе улучшена в несколько раз. Это помогает улучшить RPO и RTO для клиентов, использующих офлайн-консолидацию для целей восстановления после сбоев (DR).
Улучшения NFS
Кэш DNLC для NFS4.1
В некоторых средах, использующих NFS4.1, имеются большие хранилища данных с сотнями ВМ, где поиск, включение или вывод списка ВМ могут быть медленнее, чем в NFSv3. Кэш поиска имен каталогов (DNLC) предназначен для уменьшения количества операций NFS LOOKUP за счет кэширования некоторых этих данных. В этом релизе была добавлена поддержка DNLC для NFS4.1. Это принесет пользу операциям, таким как "ls" в каталоге с большим количеством ВМ или файлов в хранилище данных.
nConnect
В vSphere 8.0 U1 появилась поддержка nConnect, которая позволяет добавлять несколько соединений к хранилищу данных NFSv3. Это может помочь снизить задержку и увеличить производительность. В Update 2 появилась поддержка динамического увеличения и уменьшения количества соединений, используемых с nConnect. В настоящее время это настраивается только через esxcli.
Недавно опубликованный компанией VMware технический документ "Troubleshooting TCP Unidirectional Data Transfer Throughput" описывает, как устранить проблемы с пропускной способностью однонаправленной (Unidirectional) передачи данных по протоколу TCP. Решение этих проблем, возникающих на хосте vSphere/ESXi, может привести к улучшению производительности. Документ предназначен для разработчиков, опытных администраторов и специалистов технической поддержки.
Передача данных по протоколу TCP очень распространена в средах vSphere. Примеры включают в себя трафик хранения между хостом VMware ESXi и хранилищем данных NFS или iSCSI, а также различные формы трафика vMotion между хранилищами данных vSphere.
В компании VMware обратили внимание на то, что даже крайне редкие проблемы с TCP могут оказывать несоразмерно большое влияние на общую пропускную способность передачи данных. Например, в некоторых экспериментах с чтением NFS из хранилища данных NFS на ESXi, кажущаяся незначительной потеря пакетов (packet loss) в 0,02% привела к неожиданному снижению пропускной способности чтения NFS на 35%.
В документе описывается методология для выявления общих проблем с TCP, которые часто являются причиной низкой пропускной способности передачи данных. Для этого производится захват сетевого трафика передачи данных в файл трассировки пакетов для офлайн-анализа. Эта трассировка пакетов анализируется на предмет сигнатур общих проблем с TCP, которые могут оказать значительное влияние на пропускную способность передачи данных.
Рассматриваемые проблемы с TCP включают в себя потерю пакетов и их переотправку (retransmission), длительные паузы из-за таймеров TCP, а также проблемы с Bandwidth Delay Product (BDP). Для проведения анализа используется решение Wireshark и описывается профиль для упрощения рабочего процесса анализа. VMware описывает системный подход к выявлению общих проблем с протоколом TCP, оказывающих значительное влияние на пропускную способность канала передачи данных - поэтому инженерам, занимающимся устранением проблем с производительностью сети, рекомендуется включить эту методологию в стандартную часть своих рутинных проверок.
В документе рассмотрены рабочие процессы для устранения проблем, справочные таблицы и шаги, которые помогут вам в этом нелегком деле. Также в документе есть пример создания профиля Wireshark с предустановленными фильтрами отображения и графиками ввода-вывода, чтобы упростить администраторам процедуру анализа.
Скачать whitepaper "Troubleshooting TCP Unidirectional Data Transfer Throughput" можно по этой ссылке.
Недавно мы писали об анонсированных новых возможностях обновленной платформы виртуализации VMware vSphere 8 Update 1, выход которой ожидается в ближайшее время. Параллельно с этим компания VMware объявила и о выпуске новой версии решения VMware vSAN 8 Update 1, предназначенного для создания высокопроизводительных отказоустойчивых хранилищ для виртуальных машин, а также об улучшениях подсистемы хранения Core Storage в обеих платформах.
Недавно компания VMware также выпустила большую техническую статью "What's New with vSphere 8 Core Storage", в которой детально рассмотрены все основные новые функции хранилищ, с которыми работают платформы vSphere и vSAN. Мы решили перевести ее с помощью ChatGPT и дальше немного поправить вручную. Давайте посмотрим, что из этого вышло :)
Итак что нового в части Core Storage платформы vSphere 8 Update 1
Одно из главных улучшений - это новая система управления сертификатами. Она упрощает возможность регистрации нескольких vCenter в одном VASA-провайдере. Это положит основу для некоторых будущих возможностей, таких как vVols vMSC. Такж есть и функции, которые касаются масштабируемости и производительности. Поскольку vVols могут масштабироваться гораздо лучше, чем традиционное хранилище, VMware улучшила подсистему хранения, чтобы тома vVols работали на больших масштабах.
1. Развертывание нескольких vCenter для VASA-провайдера без использования самоподписанных сертификатов
Новая спецификация VASA 5 была разработана для улучшения управления сертификатами vVols, что позволяет использовать самоподписанные сертификаты для многовендорных развертываний vCenter. Это решение также решает проблему управления сертификатами в случае, когда независимые развертывания vCenter, работающие с различными механизмами управления сертификатами, работают вместе. Например, один vCenter может использовать сторонний CA, а другой vCenter может использовать сертификат, подписанный VMCA. Такой тип развертывания может быть использован для общего развертывания VASA-провайдера. Эта новая возможность использует механизм Server Name Indication (SNI).
SNI - это расширение протокола Transport Layer Security (TLS), с помощью которого клиент указывает, какое имя хоста он пытается использовать в начале процесса handshake. Это позволяет серверу показывать несколько сертификатов на одном IP-адресе и TCP-порту. Следовательно, это позволяет обслуживать несколько безопасных (HTTPS) веб-сайтов (или других служб через TLS) с одним и тем же IP-адресом, не требуя, чтобы все эти сайты использовали один и тот же сертификат. Это является концептуальным эквивалентом виртуального хостинга на основе имени HTTP/1.1, но только для HTTPS. Также теперь прокси может перенаправлять трафик клиентов на правильный сервер во время хэндшейка TLS/SSL.
2. Новая спецификация vVols VASA 5.0 и некоторые детали функций
Некоторые новые функции, добавленные в vSphere 8 U1:
Изоляция контейнеров - работает по-разному для поставщиков VASA от различных производителей. Она позволяет выполнять настройку политики контроля доступа на уровне каждого vCenter, а также дает возможность перемещения контейнеров между выбранными vCenter. Это дает лучшую изоляцию на уровне контейнеров, а VASA Provider может управлять правами доступа для контейнера на уровне каждого vCenter.
Аптайм - поддержка оповещений об изменении сертификата в рамках рабочего процесса VASA 5.0, который позволяет обновлять сертификат VMCA в системах с несколькими vCenter. Недействительный или истекший сертификат вызывает простой, также возможно возникновение простоя при попытке регистрации нескольких vCenter с одним VASA Provider. В конфигурации с несколькими vCenter сертификаты теперь можно обновлять без простоя.
Улучшенная безопасность для общих сред - эта функция работает по-разному для поставщиков VASA от производителей. Все операции могут быть аутентифицированы в контексте vCenter, и каждый vCenter имеет свой список контроля доступа (ACL). Теперь нет самоподписанных сертификатов в доверенном хранилище. VASA Provider может использоваться в облачной среде, и для этого также есть доступная роль в VASA 5.0.
Обратная совместимость - сервер ESXi, который поддерживает VASA 5.0, может решать проблемы с самоподписанными сертификатами и простоями, возникающими в случае проблем. VASA 5.0 остается обратно совместимым и дает возможность контролировать обновление в соответствии с требованиями безопасности. VASA 5.0 может сосуществовать с более ранними версиями, если производитель поддерживает эту опцию.
Гетерогенная конфигурация сертификатов - работает по-разному для поставщиков VASA от производителей. Теперь используется только подписанный сертификат VMCA, дополнительный CA не требуется. Это позволяет изолировать доверенный домен vSphere. VASA 5.0 позволяет использовать разные конфигурации для каждого vCenter (например, Self-Managed 3rd Party CA Signed Certificate и VMCA managed Certificate).
Не необходимости вмешательства администратора - поддержка многократного развертывания vCenter с использованием VMCA, которая не требует от пользователя установки и управления сертификатами для VP. Служба SMS будет отвечать за предоставление сертификатов. Теперь это работает в режиме Plug and Play с автоматической предоставлением сертификатов, без вмешательства пользователя, при этом не требуется никаких ручных действий для использования VASA Provider с любым vCenter.
Комплаенс безопасности - отсутствие самоподписанных сертификатов в доверенных корневых центрах сертификации позволяет решить проблемы соответствия требованиям безопасности. Не-СА сертификаты больше не являются частью хранилища доверенных сертификатов vSphere. VASA 5.0 требует от VASA Provider использовать сертификат, подписанный СА для связи с VASA.
3. Перенос Sidecar vVols в config-vvol вместо другого объекта vVol
Sidecars vVols работали как объекты vVol, что приводило к накладным расходам на операции VASA, такие как bind/unbind. Решения, такие как First Class Disks (FCD), создают большое количество маленьких sidecars, что может ухудшить производительность vVols. Кроме того, поскольку может быть создано множество sidecars, это может учитываться в общем количестве объектов vVol, поддерживаемых на массиве хранения. Чтобы улучшить производительность и масштабируемость, теперь они обрабатываются как файлы на томе config-vvol, где могут выполняться обычные операции с файлами. Не забывайте, что в vSphere 8 был обновлен способ байндига config-vvol. В результате, с новым механизмом config-vvol уменьшается число операций и задержки, что улучшает производительность и масштабируемость.
Для этой функциональности в этом релизе есть несколько ограничений при создании ВМ. Старые виртуальные машины могут работать в новом формате на обновленных до U1 хостах, но сам новый формат не будет работать на старых ESXi. То есть новые созданные ВМ и виртуальные диски не будут поддерживаться на хостах ниже версии ESXi 8 U1.
5. Улучшения Config-vvol, поддержка VMFS6 config-vvol с SCSI vVols (вместо VMFS5)
Ранее Config-vvol, который выступает в качестве каталога для хранилища данных vVols и содержимого VM home, был ограничен размером 4 ГБ. Это не давало возможности использования папок с хранилищем данных vVols в качестве репозиториев ВМ и других объектов. Для преодоления этого ограничения Config-vvol теперь создается как тонкий объект объемом 255 ГБ. Кроме того, вместо VMFS-5 для этих объектов будет использоваться формат VMFS-6. Это позволит размещать файлы sidecar, другие файлы VM и библиотеки контента в Config-vvol.
На изображении ниже показаны Config-vvol разных размеров. Для машины Win10-5 Config-vvol использует исходный формат 4 ГБ, а ВМ Win10-vVol-8u1 использует новый формат Config-vvol объемом 255 ГБ.
6. Добавлена поддержка NVMe-TCP для vVols
В vSphere 8 была добавлена поддержка NVMe-FC для vVols. В vSphere 8 U1 также расширена поддержка NVMe-TCP, что обеспечивает совместное использование NVMeoF и vVols. См. статью vVols with NVMe - A Perfect Match | VMware.
7. Улучшения NVMeoF, PSA, HPP
Инфраструктура поддержки NVMe end-to-end:
Расширение возможностей NVMe дает возможность поддержки полного стека NVMe без какой-либо трансляции команд SCSI в NVMe на любом уровне ESXi. Еще одной важной задачей при поддержке end-to-end NVMe является возможность контроля multipath-плагинов сторонних производителей для управления массивами NVMe.
Теперь с поддержкой GOS протокол NVMe может использоваться для всего пути - от GOS до конечного таргета.
Важным аспектом реализации VMware трансляции хранилищ виртуальных машин является поддержка полной обратной совместимости. VMware реализовала такой механизм, что при любом сочетании виртуальных машин, использующих SCSI или контроллер vNVMe, и целевого устройства, являющегося SCSI или NVMe, можно транслировать путь в стеке хранения. Это дизайн, который позволяет клиентам переходить между SCSI- и NVMe-хранилищами без необходимости изменения контроллера хранилищ для виртуальной машины. Аналогично, если виртуальная машина имеет контроллер SCSI или vNVMe, он будет работать как на SCSI-, так и на NVMeoF-хранилищах.
Упрощенная диаграмма стека хранения выглядит так:
Для получения дополнительной информации о NVMeoF для vSphere, обратитесь к странице ресурсов NVMeoF.
8. Увеличение максимального количества путей для пространств имен NVMe-oF с 8 до 32
Увеличение количества путей улучшает масштабирование в окружениях с несколькими путями к пространствам имен NVMe. Это необходимо в случаях, когда хосты имеют несколько портов и модуль имеет несколько нод, а также несколько портов на одной ноде.
9. Увеличение максимального количества кластеров WSFC на один хост ESXi с 3 до 16
Это позволяет уменьшить количество лицензий Microsoft WSFC, необходимых для увеличения количества кластеров, которые могут работать на одном хосте.
Для получения дополнительной информации о работе Microsoft WSFC на vSphere можно обратиться к следующим ресурсам:
10. Улучшения VMFS - расширенная поддержка XCOPY для копирования содержимого датасторов между различными массивами
ESXi теперь поддерживает расширенные функции XCOPY, что оптимизирует копирование данных между датасторами разных массивов. Это поможет клиентам передать обработку рабочих нагрузок на сторону хранилища. Функция уже доступна в vSphere 8 U1, но по факту миграция данных между массивами должна поддерживаться на стороне хранилища.
11. Реализация NFSv3 vmkPortBinding
Данная функция позволяет привязать соединение NFS для тома к конкретному vmkernel. Это помогает обеспечить безопасность, направляя трафик NFS по выделенной подсети/VLAN, и гарантирует, что трафик NFS не будет использовать mgmt-интерфейс или другие интерфейсы vmkernel.
Предыдущие монтирования NFS не содержат этих значений, хранящихся в config store. Во время обновления, при чтении конфигурации из конфигурационного хранилища, значения vmknic и bindTovmnic, если они есть, будут считаны. Поэтому обновления с предыдущих версий не будут содержать этих значений, так как они являются необязательными.
Изменения в способе создания/удаления Swap-файлов для томов vVols помогли улучшить производительность включения/выключения, а также производительность vMotion и svMotion.
13. Улучшения Config vVol и сохранение привязки
Здесь были сделаны следующие доработки:
Уменьшено время запроса при получении информации о ВМ
Добавлено кэширование атрибутов vVol - размер, имя и прочих
Конфигурационный vVol - это место, где хранятся домашние файлы виртуальной машины (vmx, nvram, logs и т. д.) и к нему обычно обращаются только при загрузке или изменении настроек виртуальной машины.
Ранее использовалась так называемая "ленивая отмена связи" (lazy unbind), и происходил unbind конфигурационного vVol, когда он не использовался. В некоторых случаях приложения все же периодически обращались к конфигурационному vVol, что требовало новой операции привязки. Теперь эта связь сохраняется, что уменьшает задержку при доступе к домашним данным виртуальной машины.
14. Поддержка NVMeoF для vVols
vVols были основным направлением развития функциональности хранилищ VMware в последние несколько версий, и для vSphere 8.0 это не исключение. Самое большое обновление в ядре хранения vSphere 8.0 - добавление поддержки vVols в NVMeoF. Изначально поддерживается только FC, но со временем будут работать и другие протоколы, провалидированные и поддерживаемые с помощью vSphere NVMeoF. Теперь есть новая спецификация vVols и VASA/VC-фреймворка - VASA 4.0/vVols 3.0.
Причина добавления поддержки vVols в NVMeoF в том, что многие производители массивов, а также отрасль в целом, переходят на использование или, по крайней мере, добавление поддержки NVMeoF для повышения производительности и пропускной способности. Вследствие этого VMware гарантирует, что технология vVols остается поддерживаемой для последних моделей хранилищ.
Еще одним преимуществом NVMeoF vVols является настройка. При развертывании после регистрации VASA фоновая установка завершается автоматически, вам нужно только создать датастор. Виртуальные эндпоинты (vPE) и соединения управляются со стороны VASA, что упрощает настройку.
Некоторые технические детали этой реализации:
ANA Group (Асимметричный доступ к пространству имен)
С NVMeoF реализация vVols немного отличается. С традиционными SCSI vVols хранилищами контейнер является логической группировкой самих объектов vVol. С NVMeoF это варьируется в зависимости от того, как поставщик массива реализует функциональность. В общем и целом, на хранилище группа ANA является группировкой пространств имен vVol. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Пространства имен выделяются и активны только по запросу BIND к провайдеру VASA (VP). Пространства имен также добавляются в группу ANA при запросе BIND к VP. Пространство имен остается выделенным/активным до тех пор, пока последний хост не отвяжет vVol.
vPE (virtual Protocol Endpoint)
Для традиционных vVols на базе SCSI, protocol endpoint (PE) - это физический LUN или том на массиве, который отображается в появляется в разделе устройств хранения на хостах. С NVMeoF больше нет физического PE, PE теперь является логическим объектом, представлением группы ANA, в которой находятся vVols. Фактически, до тех пор, пока ВМ не запущена, vPE не существует. Массив определяет количество групп ANA, каждая из которых имеет уникальный ANAGRPID в подсистеме NVM. Как только ВМ запущена, создается vPE, чтобы хост мог получить доступ к vVols в группе ANA. На диаграмме ниже вы можете увидеть, что vPE указывает на группу ANA на массиве.
NS (пространство имен, эквивалент LUN в NVMe)
Каждый тип vVol (Config, Swap, Data, Mem), созданный и использующийся машиной, создает NS, который находится в группе ANA. Это соотношение 1:1 между vVol и NS позволяет вендорам оборудования легко масштабировать объекты vVols. Обычно поставщики поддерживают тысячи, а иногда и сотни тысяч NS. Ограничения NS будут зависеть от модели массива.
На диаграмме вы можете увидеть, что сама виртуальная машина является NS, это будет Config vVol, а диск - это другой NS, Data vVol.
Поддержка 256 пространств имен и 2K путей с NVMe-TCP и NVMe-FC
NVMeoF продолжает набирать популярность по очевидным причинам - более высокая производительность и пропускная способность по сравнению с традиционным подключением SCSI или NFS. Многие производители хранилищ также переходят на NVMe-массивы и использование SCSI для доступа к NVMe флэш-накопителям является узким местом и потенциалом для улучшений.
Продолжая работать на этим, VMware увеличила поддерживаемое количество пространств имен и путей как для NVMe-FC, так и для TCP.
Расширение reservations для устройств NVMe
Добавлена поддержка команд reservations NVMe для использования таких решений, как WSFC. Это позволит клиентам использовать возможности кластеризованных дисков VMDK средствами Microsoft WSFC с хранилищами данных NVMeoF. Пока поддерживается только протокол FC.
Поддержка автообнаружения для NVMe Discovery Service на ESXi
Расширенная поддержка NVMe-oF в ESXi позволяет динамически обнаруживать совместимые со стандартом службы NVMe Discovery Service. ESXi использует службу mDNS/DNS-SD для получения информации, такой как IP-адрес и номер порта активных служб обнаружения NVMe-oF в сети.
Также ESXi отправляет многоадресный DNS-запрос (mDNS), запрашивая информацию от сущностей, предоставляющих службу обнаружения DNS-SD. Если такая сущность активна в сети (на которую был отправлен запрос), она отправит (одноадресный) ответ на хост с запрошенной информацией - IP-адрес и номер порта, где работает служба.
16. Улучшение очистки дискового пространства с помощью Unmap
Снижение минимальной скорости очистки до 10 МБ/с
Начиная с vSphere 6.7, была добавлена функция настройки скорости очистки (Unmap) на уровне хранилища данных. С помощью этого улучшения клиенты могут изменять скорость очистки на базе рекомендаций поставщика их массива. Более высокая скорость очистки позволяла многим пользователям быстро вернуть неиспользуемое дисковое пространство. Однако иногда даже при минимальной скорости очистки в 25 МБ/с она может быть слишком высокой и привести к проблемам при одновременной отправке команд Unmap несколькими хостами. Эти проблемы могут усугубляться при увеличении числа хостов на один датастор.
Пример возможной перегрузки: 25 МБ/с * 100 хранилищ данных * 40 хостов ~ 104 ГБ/с
Чтобы помочь клиентам в ситуациях, когда скорость очистки 25 МБ/с может приводить к проблемам, VMware снизила минимальную скорость до 10 МБ/с и сделала ее настраиваемой на уровне датасторов:
При необходимости вы также можете полностью отключить рекламацию пространства для заданного datastore.
Очередь планирования отдельных команд Unmap
Отдельная очередь планирования команд Unmap позволяет выделить высокоприоритетные операции ввода-вывода метаданных VMFS и обслуживать их из отдельных очередей планирования, чтобы избежать задержки их исполнения из-за других команд Unmap.
17. Контейнерное хранилище CNS/CSI
Теперь вы можете выбрать политику Thin provisioning (EZT, LZT) через SPBM для CNS/Tanzu.
Цель этого - добавить возможность политик SPBM для механизма создания/изменения правил политик хранения, которые используются для параметров выделения томов. Это также облегчает проверку соответствия правил выделения томов в политиках хранения для SPBM.
Операции, поддерживаемые для виртуальных дисков: создание, реконфигурация, клонирование и перемещение.
Операции, поддерживаемые для FCD: создание, обновление политики хранения, клонирование и перемещение.
18. Улучшения NFS
Инженеры VMware всегда работают над улучшением надежности доступа к хранилищам. В vSphere 8 были добавлены следующие улучшения NFS, повышающие надежность:
Повторные попытки монтирования NFS при сбое
Валидация монтирования NFS
Ну как вам работа ChatGPT с правками человека? Читабельно? Напишите в комментариях!
Совсем недавно вышел новый релиз Vinchin Backup & Recovery V7.0, который уже доступен для скачивания. Сегодня мы поговорим о продуктах и технологиях компании Vinchin для резервного копирования виртуальных машин и обеспечения защиты данных виртуального датацентра. В первой части мы расскажем о кратком обзоре вебинара Vinchin Backup & Recovery V7.0, который прошел 1 марта...
Итак, публикуем четвертую часть нашего большого рассказа о новых возможностях главного решения для резервного копирования и репликации виртуальных машин компании Veeam - Backup & Replication v12, которое уже доступно для скачивания.
Сегодня мы поговорим о плагинах приложений, виртуальных модулях Backup Proxy, а также резервном копировании контейнеров и NAS-хранилищ.
1. Плагины приложений
Управление плагинами:
Centralized application plug-in management - мастер Protection Group был расширен дополнительными настройками для контроля над установкой и обновлениями плагинов приложений на включенных в группу серверах. Теперь есть сбор информации о топологии приложений и обнаружение систем Oracle RAC и SAP HANA при сканировании и ресканировании.
Certificate-based TLS authentication - Protection Groups теперь используют аутентификацию на базе сертификатов при установке соединения с плагинами.
Application backup policy - появилась возможность оркестрации бэкапов Oracle RMAN, SAP HANA и SAP on Oracle на базе политик из бэкап-консоли, что позволяет избавиться от ручного обслуживания конфигураций плагинов и бэкап-сценариев на каждом сервере БД.
Granular database-level protection settings - политики бэкапа приложений поддерживают различные настройки для отдельных БД. Каждая политика может быть применена к своему набору баз данных.
Centralized backup monitoring - политики бэкапа приложений имеют средство для мониторинга процесса РК на каждом сервере в реальном времени, визуализации статистики и отчетов для бэкапов баз данных и redo-логов.
Recovery tokens - бэкап-администраторы теперь могут сгенерировать временные токены для бэкап-плагинов. Они могут быть использованы для соединения с репозиториями и восстановления баз данных с помощью нативных утилит, без необходимости назначения пользователю постоянной роли.
Плагин для Microsoft SQL Server:
Новый плагин предоставляет глубокую интеграцию с Microsoft SQL Server (VDI-плагин), что позволяет делать прямой бэкап напрямую в репозитории Veeam.
VDI-плагин использует нативные средства для обеспечения консистентности бэкапов, и, в отличие от бэкапов на базе снапшотов, не завязан на Microsoft VSS, что позволяет делать резервные копии разных конфигураций SQL Server, таких как Windows Server Failover Clusters с томами shared volumes. Теперь плагин может защитить до 2000 баз данных на один SQL-сервер и до 10000 БД на бэкап-сервер.
Плагин был полностью переработан, чтобы защищать разные конфигурации SQL Server, такие как SQL Always On, где задачи РК автоматически считывают данные с предпочитаемого сервера реплики.
Теперь интерфейс плагина полностью интегрирован с Microsoft SQL Server Management Studio, где он может быть запущен по клику на иконку в тулбаре. Также стандартный бэкап баз данных на репозитории Veeam полностью поддерживается. Сам же плагин может создавать задачи SQL Server Agent прямо из графического интерфейса.
Задачи Backup Copy поддерживают нативные бэкапы SQL на вторичные репозитории, а если вы хотите избежать управления этими дополнительными задачами, то можно использовать SOBR для Capacity Tier в режиме Copy mode.
Анализ цепочек бэкапов позволяет разгрузить процедуру РК за счет перемещения неактивных бэкапов с помощью политики Move policy для освобождения дискового пространства на Performance Tier, а также убедиться, что период immutability корректно пролонгирован для активных цепочек бэкапов.
Плагины для Oracle RMAN и SAP HANA:
Performance improvements — в V12 до 3х увеличена скорость резервного копирования и восстановления. Это было сделано за счет улучшений data movers, которые забирают данные напрямую из приложения, минуя промежуточный процесс plug-in manager.
Reduced impact on production environment - теперь не нужно запускать выделенный data mover для каждого backup channel, что уменьшает количество муверов, которые запущены на сервере БД. Планировщик следит за тем, чтобы дата муверов было не более, чем в два раза больше, чем доступных ядер CPU.
Linux ACL support for configuration files - можно использовать группы в Linux для запрета изменений конфигурации плагина бэкап-операторами.
2. Виртуальные модули Backup Proxy
Veeam Backup for AWS - здесь добавлены immutable-бэкапы инстансов EC2 для хранилищ AWS S3, улучшения масштабируемости для больших окружений, поддержка GP3-дисков для виртуального модуля, поддержка multi-tenant контейнера для Oracle, поддержка OAuth 2.0 для email-нотификаций, интеграция с Veeam Service Provider Console и поддержка Veeam Universal License (VUL), а также другие возможности.
Veeam Backup for Microsoft Azure - тут была добавлена поддержка immutable-бэкапов для Azure VM и Azure SQL в хранилище Azure Blob storage, улучшения масштабируемости для больших окружений, контроль нагрузки для репозиториев, поддержка OAuth 2.0 для email-нотификаций, интеграция с Veeam Service Provider Console и поддержка Veeam Universal License (VUL), а также другие возможности.
Veeam Backup for Google Cloud - тут была добавлена гранулярная защита для баз данных PostgreSQL, возможность хранить снапшоты инстансов в одном регионе, улучшены средства управления для cross-project service accounts, добавлена возможность использовать папки организации как источник политик, а также реализована поддержка Veeam Universal License (VUL).
Veeam Backup for Nutanix AHV - переработан интерфейс, добавлена возможность прямого бэкапа в object storage, поддержка immutable и synthetic full бэкапов, политики хранения GFS, защита от повреждения хранилищ, REST API для управления бэкапом и восстановлением. Также увеличена производительность и добавлена поддержка Instant VM Recovery из репозиториев Veeam Cloud Connect.
Veeam Backup for Red Hat Virtualization (RHV) - добавлена возможность прямого бэкапа в object storage, поддержка immutable и synthetic full бэкапов, политики хранения GFS, защита от повреждения хранилищ и сделано множество улучшений интерфейса.
3. Резервное копирование контейнеров
Kasten K10 Backup for Kubernetes integration - инстансы K10 теперь могут быть зарегистрированы на бэкап-сервере, что позволяет просмотреть все политики РК для Kubernetes, а также сессии и бэкапы напрямую из backup console, вне зависимости от того, хранятся ли они в репозиториях Veeam или в другом месте. Вызов редактирования политик и операций по восстановлению перенаправляет пользователя в контекстный рабочий процесс K10 и позволяет завершить его через K10 web UI.
4. Резервное копирование NAS-хранилищ
Общие улучшения:
SMB over QUIC support - теперь задачи РК файловых шар могут получать данные по SMB более безопасно и эффективно через протокол QUIC.
Recovery throttling support - при восстановлении бэкапов можно управлять загрузкой сетевого канала.
Improved search performance - новая функциональность поиска работает на 25% быстрее, как в backup console, так и в Veeam Backup Enterprise Manager web UI.
Storage-level corruption guard enhancements - теперь проверка состояния процессов включает в себя оповещения пользователя о возможных проблемах с архивированными метаданными.
NFS fs_locations support - теперь бэкап файловых шар понимает концепцию NFS referrals, что позволяет организовать защиту более комплексных распределенных файловых систем NFS.
Бэкап на диск:
Copy mode - в дополнение к архивированию старых версий файлов, которые не включены в политику хранения бэкапов, теперь есть опция заархивировать также и текущие версии. В этом случае архив будет содержать полную копию бэкапа, для которого будет доступно полное восстановление файловой шары к последнему состоянию напрямую из архивного репозитория.
Expanded exclusion rules - теперь можно исключить отдельные шары из копирования в виде \share\folder\path, добавив путь для правил исключений. В этих правилах можно использовать астериски вида *\folder (поддерживается только для одного уровня папок). Также по умолчанию из процессинга исключаются папки \ipc$, \admin$ и \c$ (это можно изменить).
Advanced backup mapping - теперь можно избежать полного бэкапа в случае переименования файловой шары с помощью PowerShell командлета Update-VBRNasBackupPath.
Бэкап на ленточные носители:
Scalable file backup engine - теперь при большом количестве файлов они объединяются в файлы образов в целях более быстрой записи на ленточные носители.
NAS backup to tape - теперь бэкапы файловых шар можно использовать как источник для задач резервного копирования на ленту в рамках подхода Disk to Disk to Tape (D2D2T). Так как это вторичный бэкап - он не требует отдельной лицензии.
Функции Instant Recovery:
Writable SMB file shares - эмулируемые SMB-шары, которые публиковались как часть instant file share recovery теперь доступны на запись, что позволяет пользователям продолжать работать с шарой в обычном режиме, включая процессы изменения существующих файлов и создания новых. Сами NAS-бэкапы не изменяются и все изменения кэшируются отдельно.
Migration to production - как только ваше хранилище NAS возвращается в онлайн, вы можете инициировать процесс восстановления самого последнего ее состояния из бэкапа. Эта операция выполняется в фоновом режиме без необходимости пользователя взаимодействовать с опубликованной файловой шарой.
Switchover - теперь есть три опции переключения восстановления для финализации instant recovery: Automatic (фоновый процесс), Scheduled (возможность отложить переключение на часы наименьшей нагрузки) и Manual (интерактивный ручной процесс). На время финализации этих процессов файловая шара будет недоступна.
Публикация:
NFS shares publishing - защищенные шары теперь могут быть опубликованы напрямую из бэкапа как эмулируемые SMB-шары. Это может быть, например, полезно для работы аналитического ПО, которое использует в качестве источника хранимые там данные.
Интеграции с файлерами:
Nutanix Filers integration - теперь можно зарегистрировать файлеры Nutanix Files в качестве источника и выполнять бэкап файлов без необходимости получать доступ к каждой защищенной файловой шаре. В этом случае бэкапы будут выполняться из нативных снапшотов хранилища, что позволяет избежать проблем с заблокированными файлами. Кроме того, бэкап теперь работает существенно быстрее благодаря поддержке технологии Nutanix Files Changed File Tracking (CFT).
Dell PowerScale (Isilon) - теперь появилась поддержка OneFS версий 9.3 и 9.4 для нативной интеграции файлеров в процесс резервного копирования.
Интеграции с хранилищами:
Rotated drive support - бэкапы файловых шар теперь поддерживают репозитории на основе ротируемых носителей.
AWS Snowball Edge support - в дополнение к поддержке Microsoft Azure Data Box теперь есть и поддержка первоначального бэкапа средствами объектного хранилища AWS Snowball Edge для последующего импорта в соответствующее публичное облако.
Ну, для четвертой части пока хватит новых фич) В следующих статьях мы продолжим рассматривать другие новые функции Veeam Backup & Replication v12, которых очень много появилось в этом большом релизе. Скачать пробную версию продукта можно бесплатно по этой ссылке.
Network-less discovery and deployment - теперь обнаружение новых рабочих нагрузок и автоматических развертываний бэкап-агентов происходит через нативный cloud API без прямого подключения к защищенным машинам.
Dynamic protection scope - теперь так же, как вы защищаете несколько онпремизных машин, указывая контейнеры и тэги, по которым происходит добавление в группу, можно создавать и Protection Groups для облачных ВМ через аналогичные конструкты в публичном облаке.
In-cloud data flow - теперь можно бэкапить ВМ в хранилища object storage того же облачного провайдера, без путешествия трафика РК через интернет, что позволяет снизить затраты на внешний трафик.
Full portability - теперь любые результирующие облачные бэкапы ВМ можно восстановить в любое целевое облако или на онпремизную площадку.
2. Функции платформы
PostgreSQL support for a configuration database - теперь поддерживается мультиплатформенный движок PostgreSQL, что позволяет избежать ограничений Microsoft SQL Server Express Edition на размер базы в 10 ГБ. Сам SQL Server Express Edition продолжает поддерживаться, но уже не включен в состав продукта Veeam Backup and Replication. Вот так база PostgreSQL выглядит в PGAdmin:
3. Движок резервного копирования
New backup chain metadata format - новый формат метаданных на уровне ВМ позволяет более удобно и гранулярно управлять функциями защиты бэкапов. Например, можно выполнять операции Active Full или Retry для отдельных машин, а не на уровне всей задачи. Также различные операции с компонентами задач теперь работают быстрее, так как не ждут завершения всей задачи.
Policy-like jobs - теперь версия V12 сочетает в себе функции управления на базе задач и функции управления на базе политик. Можно создавать очень большие задачи с тысячами машин, перемещать бэкапы между задачами и выполнять прочие действия, которые работают по аналогии с таковыми в стиле политик защиты данных.
Background retention - ранее функции автоматической ротации и удаления старых копий работали для GFS-хранилищ, а сейчас они доступны вообще для всех бэкапов (в том числе для отключенных задач, с использованием их последней активной retention policy). Этот процесс автоматически запускается в полночь, но может быть и запущен вручную.
4. Управление данными бэкапов
VeeaMover - это новый движок перемещения данных между репозиториями различных типов. Теперь вам не нужно думать о типе исходного и целевого репозитория - VeeaMover автоматически сделает всю работу по перемещению данных.
Block clone awareness - теперь при клонировании ВМ на уровне блоков для ReFS/XFS/object storage при миграциях происходит существенная экономия дискового пространства по аналогии с перемещением файлов бэкапа с хранилищ SMB на XFS.
Streamlined repository change processes - теперь можно переместить все данные репозитория в другое место с помощью VeeaMover и далее просто сделать его апгрейд.
Move backups between jobs - теперь бэкапы можно просто перемещать между задачами и все сопутствующие операции будут выполнены автоматически (например, работа со списками inclusion и exclusion).
Copy backups between repositories - теперь всю цепочку бэкапов можно переместить в другое место в несколько кликов, при этом политика retention policy сохранится (но можно и изменить ее).
5. Инфраструктура резервного копирования
Работа с репозиториями:
Multiple gateway server support - в дополнение к автоматическому выбору шлюза вы теперь можете указать пул шлюзовых серверов, который вы хотите использовать для передачи данных от/к определенному бэкап-репозиторию. Шлюзы в рамках пула приоритизируются по скорости соединения и текущей нагрузке по задачам. Использование нескольких шлюзов полезно при использовании конфигураций хранилищ Fibre Channel (FC) для обеспечения избыточности каналов передачи данных и необходимого уровня производительности.
Rotated drives cleanup - теперь при переключении на ротируемые носители происходит автоматическая очистка дисков от существующих там старых бэкапов. Пользователи также могут продолжить использование существующей цепочки бэкапов, а также выбрать один из двух вариантов: удалить бэкапы, которые относятся только к текущей задаче, либо удалить все бэкапы на носителе.
Функции Scale-out Backup Repository (SOBR):
Object storage as performance extent - теперь Performance Tier может использовать экстенты object storage в дополнение к экстентам блочных и файловых хранилищ.
Support for multiple object storage extents - Performance Tier и Capacity Tier могут использовать несколько экстентов object storage. Это полезно, когда объектное хранилище поддерживает ограниченное число объектов на узел. В этом случае для дополнительных экстентов будет использоваться балансировка round-robin на уровне ВМ.
Direct to archive - при использовании AWS S3 или Microsoft Azure Blob Storage как экстентов вы можете пропустить настройку Capacity Tier. В этом случае бэкапы будут сразу перемещаться из Performance Tier на Archive Tier.
Glacier Instant Retrieval support - в этом обновлении была добавлена поддержка класса хранилищ Glacier в качестве Archive Tier. В этом случае производительность будет обеспечиваться на уровне классов хранилищ S3 Standard и S3 Standard-IA, чтобы быстро получить доступ к архивным резервным копиям.
SOBR rebalance - теперь можно выполнить ребалансировку потребления хранилищ на уровне блочных и файловых хранилищ для экстентов Performance Tier, чтобы выровнять распределение данных между ними. Эту операцию нужно выполнять тогда, когда вы хотите добавить новый экстент, постоянно выполнять ее не нужно.
VeeaMover integration - операции Extent evacuation и SOBR rebalance используют новый движок VeeaMover, чтобы более эффективно перемещать бэкапы между экстентами.
Strict data placement policy enforcement - по умолчанию SOBR мог нарушать политику размещения данных, чтобы убедиться, что бэкап был записан на носитель. Теперь же можно включить опцию, когда в этом случае задача РК завершится с ошибкой.
Функции управления трафиком:
Support for multiple internet rules - теперь по просьбе пользователей добавлены несколько интернет-правил для управления трафиком в окружениях с несколькими площадками и сетями.
Time-based throttling level - теперь есть более гибкие функции по регулированию использования канала, в зависимости от времени дня, чтобы не создавать большую нагрузку на инфраструктуру. Теперь есть настройка Unthrottle для различных регуляций трафика в часы наименьшей нагрузки.
Restore traffic throttling options - теперь правила регулирования трафика распространяются и на процессы восстановления, а не только на процесс резервного копирования.
Нотификации по электронной почте:
OAuth 2.0 support for email notifications - теперь в дополнение к аутентификации через SMTP продукт поддерживает и авторизацию через протокол OAuth в Google Gmail и Microsoft 365.
Active instant recoveries - теперь ежедневные отчеты напомнят пользователю обо всех активных сессиях Instant Recovery, которые еще не завершились.
Full product version display - отчеты теперь включают в себя полную версию сервера, включая уровень патча.
Поддержка VMware vSphere:
VMware vSphere Linux backup proxy enhancements - теперь появилась поддержка прямого доступа к хранилищу для режима транспорта, которая позволяет прокси на базе Linux выполнять прямое резервное копирование из снапшотов NFS-хранилищ.
Hardened repository as a backup proxy - теперь можно использовать защищенный репозиторий как бэкап-прокси в режиме NBD. В этом случае недоступны функции режимов Advanced transport, так как они требуют доступа root, что небезопасно.
Improved replication performance - виртуальные машины со снапшотами SeSparse (на хранилищах VMFS-6) будут реплицироваться быстрее, так как их копирование будет проходить в асинхронном режиме.
Backup I/O control latency minimums - учитывая новые хранилища All-Flash настройки latency теперь можно регулировать на уровне миллисекунд.
Поддержка Microsoft Hyper-V:
Infrastructure caching - так же, как и для vSphere, бэкап-сервер теперь кэширует информацию хостов Hyper-V для уменьшения запросов через интерфейс WMI. Это увеличивает производительность задач РК и отклик интерфейса консоли в больших инфраструктурах.
Compatibility checker enhancements - теперь можно восстанавливать и реплицировать ВМ на хосты Hyper-V меньшей версии, чем изначальные, если там поддерживается соответствующая версия VM hardware.
В следующих статьях мы продолжим рассматривать другие новые функции Veeam Backup & Replication v12, которых очень много появилось в этом большом релизе. Скачать пробную версию продукта можно бесплатно по этой ссылке.
Недавно компания Veeam Software, главный производитель средств для резервного копирования и защиты данных виртуальных инфраструктур, анонсировала выпуск новой версии Veeam Backup & Replication v12. Ну а на днях финальная версия этого продукта стала доступной для скачивания. Давайте посмотрим, что там появилось нового в части прямого резервного копирования в объектные хранилища, неизменяемых бэкапов и безопасности.
Новые возможности сгруппированы по категориям. Это одно из самых насыщенных обновлений продукта, поэтому мы решили разбить рассказ о новых возможностях на несколько статей. Итак:
1. Прямое резервное копирование в объектное хранилище
Direct-to-Object - теперь данные бэкапов передаются напрямую из бэкап-прокси и агентов в объектное хранилище, минуя промежуточные шаги. Также, если прямое соединение с таким хранилищем недоступно, то можно перенаправить трафик через отказоустойчивый пул серверов-шлюзов.
Direct-to-Cloud - в новой версии доступно более эффективное прямое резервное копирование в облако, в том числе из окружений Remote Office Branch Office (ROBO). По-прежнему, Veeam рекомендует иметь также и локальные резервные копии у себя в датацентре в рамках правила 3-2-1 (3 копии данных, 2 разных носителя, 1 облачная копия вне площадки).
Immutable backups - функция неизменяемости резервных копий (даже со стороны администратора), которая доступна в локальных и облачных окружениях). Это позволяет избежать шифрования бэкапов со стороны вредоносного ПО (Ransomware). Такие резервные копии защищаются в течение всего своего жизненного цикла хранения.
Spaceless full backups - это репозитории на базе файловых систем ReFS и XFS, когда бэкапы записываются напрямую в объектное хранилище. Такой бэкап не потребляет дополнительного дискового места, кроме непосредственно основных хранимых данных.
Improved storage format - теперь формат хранения данных бэкапов существенно оптимизирован, в том числе теперь нет необходимости в синхронизации локальных и облачных индексов.
Health check light - теперь задачи, управляемые агентами и использующие объектные хранилища, могут быть полностью просканированы на возможные повреждения данных. Это сканирование проводится только по мере необходимости, что не нагружает инфраструктуру, но пользователь может самостоятельно запустить полное сканирование.
Wasabi integration - теперь Wasabi входит в число партнеров в области облачных объектных хранилищ, для чего теперь есть отдельный пользователь интерфейс для доступа к репозиторию Wasabi Hot Cloud Storage.
Smart Object Storage API - это новый программный интерфейс (SOSAPI), который позволяет вендорам объектных хранилищ глубоко интегрироваться с решением Veeam Backup & Replication v12 для лучшей производительности и качества пользовательского опыта. Например, можно направить бэкап конкретной машины на специфический бэкап-узел для более быстрого бэкапа. SOSAPI-интеграции могут использовать функции Scality (программные хранилища) и Object First (аппаратные модули).
2. Расширенные функции immutability
Immutability for more backup types - теперь в дополнение к поддержке бэкапов на уровне образов функции неизменяемости резервных копий доступны и для NAS-хранилищ, standalone-агентов, бэкапов в AWS и Microsoft Azure, а также для транзакционных логов и enterprise-приложений через плагины.
Hardened repository improvements - теперь для апгрейдов компонентов защищенных репозиториев не требуется соединение с сервером по SSH. Это упрощает управление инфраструктурой репозиториев и позволяет не думать об их дополнительной защите. Также теперь в интерфейсе Veeam B&R есть специальный мастер для защищенной конфигурации, а также есть специальный тип защищенного репозитория, в который можно сконвертировать существующие в автоматическом режиме.
Microsoft Azure Blob Storage immutability support — теперь есть поддержка неизменяемых бэкапов для Blob-хранилищ. Она пока не работает для Managed-by-Agent задач ввиду ограничений Azure API, а также для репозиториев Veeam Cloud Connect, когда они работают в режиме direct transfer mode (без шлюзовых серверов).
HPE StoreOnce immutability support - в 12-й версии поддерживается создание неизменяемых бэкапов на хранилищах Catalyst Stores, где эта функция контролируется со стороны сервис-провайдера.
3. Безопасность и аудит
Multi-factor authentication - теперь доступ к консоли возможен через функцию two-factor authentication (2FA), который основан на механике одноразовых кодов Time-Based One-Time Passwords (TOTP) в соответствии с RFC 6238. Это можно включить для отдельных аккаунтов.
Kerberos-only authentication - теперь V12 можно развернуть в окружениях, где аутентификация NTLM отключена в целях повышенной безопасности. Аутентификация Kerberos поддерживается для всех компонентов инфраструктуры резервного копирования прямо из коробки. Машины можно регистрировать по DNS-именам (для Kerberos не поддерживаются IP-адреса). Для NFS хранилищ вам потребуется дополнительная конфигурация (см. User Guide).
IPv6 support - теперь поддержка IPv6 доступна для всех типов сетей (IPv6-only и dual-stack), что позволяет постепенно переходить на IPv6.
gMSA accounts for Windows - теперь для гостевых ОС Windows доступен application-aware процессинг через беспарольные аккаунты Group Managed Service Accounts (gMSA), чтобы не хранить пароли в конфигурации бэкап-серверов.
Single-use credentials for Linux - теперь для гостевых ОС Linux восстановление и управление процессом резервного копирования может быть настроено на базе сертификатов, без необходимости хранить пароли в конфигурации сервера. После этой настройки можно отключить и SSH.
Improved audit logs and alerts - в Windows Event Log и в логи аудита было добавлено более 90 дополнительных событий, включая различные задачи, выполняемые администратором. Если в лог не получается добавить запись - то сервер отправляет алерт как SNMP trap.
Automatic console lockouts - теперь есть настраиваемая блокировка консоли для простаивающих сессий.
Best practices analyzer - теперь этот компонент проверяет бэкап-сервер и конфигурацию продукта, после чего предлагает важные изменения, которые могут улучшить безопасность и шансы на удачное восстановление.
В следующих статьях мы рассмотрим другие новые функции Veeam Backup & Replication v12, которых очень много появилось в этом большом релизе. Скачать пробную версию продукта можно бесплатно по этой ссылке.
Многие облачные администраторы VMware знакомы с продуктом Cloud Provider Lifecycle Manager, который позволяет обеспечивать непрерывный процесс обновления компонентов облачной платформы (ранее его функции частично выполнял Update Manager). При этом Lifecycle Manager поддерживает управление жизненным циклом и таких решений, как VMware Cloud Director, Usage Meter и vRealize Operations Manager Tenant App средствами дополнительного пакета interop bundle, который содержит определения по совместимости вышедших версий продуктов с другими платформами.
В прошлом году на конференции VMworld 2021 было объявлено о том, что теперь с помощью VMware Cloud Provider Lifecycle Manager (VCPLM) можно автоматизировать рутинные операции жизненного цикла пользователей, разрабатывая свои сценарии развертывания, обслуживания и списания систем, что позволяет сотрудникам сервис-провайдеров сосредоточиться на более высокоуровневых операциях. При этом такие решения, как interop bundle отлично дополняют экосистему обновлений, доставляемых через Lifecycle Manager.
1. Улучшенный выбор сетей для сетевых адаптеров узлов
Он теперь дает возможность фильтрации групп портов, а также можно вбивать только часть имени сети:
2. Улучшенная логика апгрейда VMware Cloud Director
При подготовке апгрейда VCD происходит бэкап шары NFS, который можно в случае чего откатить в рамках процесса rollback. Также процедура обновления теперь ждет, пока апгрейд закончится на всех элементах инфраструктуры. Это дает побольше надежность, но несколько увеличивает время апгрейда. Регулировать таймаут в секундах можно с помощью команды:
su -c "echo CPLCM_VCD_UPGRADE_PROCESS_TIMEOUT=3600 >> /etc/environment; systemctl restart vcplcm-api.service"
3. Улучшенное обновление сертификатов VCD
Сертификаты теперь устанавливаются более надежно - добавлена дополнительная верификация самих сертификатов и ключей.
4. Прочие улучшения
Здесь можно отметить следующие вещи:
Поддержка Chargeback 8.10 (бывшее решение vRealize Operations Manager Tenant App)
Развертывание Interop Bundle происходит следующим образом:
Переходим в VMware Cloud Provider Lifecycle Manager UI, для чего нужно вбить адрес https://vcplcmhost-name и залогиниться как пользователь vcplcm. В верхней панели выбираем Administration и идем на страницу Troubleshooting:
Здесь можно проверить наличие обновления для Interop Bundle и накатить его. Нажимаем Update Interop Bundle и затем Install Interop Bundle:
После успешного обновления вы получите сообщение "Interop bundle has been updated":
Нажмите Check for the Interop Bundle update, чтобы убедиться, что у вас установлена последняя версия:
Также версию продукта можно проверить в разделе VMware Cloud Provider Lifecycle Manager UI > About:
Скачать Interop Bundle 1.4.8 для VMware Cloud Provider Lifecycle Manager 1.4 можно по этой ссылке. Release Notes доступны тут.

 RSS
RSS